Technology trends over the past decade
by SoftwareMill engineers
The 2010s were a decade of great innovation, driven by the rise of data and acceleration in IT and technology. Together with our software engineers, we hand-picked the most important milestones and interesting events that have, in our opinion, changed the way we live significantly.
Let's dive deep into cloud computing, machine learning, IoT, and software development innovations that define how we build valuable software products.

Cloud technology and data-intensive computing
In the last decade, the total amount of data created and consumed globally grew from 2 zettabytes to 64.2 zettabytes. We are in the zettabytes era. How much is this exactly?
Imagine a bee building a honeycomb. Let's say one honeycomb cell has a diameter of 6mm and carries 1GB of data. If such cells were placed one on top of another, in 2010, the bee would have flown behind the Moon 30 times. In 2020, it would have already reached Mars.
If the trend continues, by 2025, the bee will almost reach Jupiter, and in the next 10 years, a bee carrying data volumes from Earth will leave our galaxy!
Data can come from a variety of sources and play an increasingly important role in today's world. It has grown exponentially to such a big value in the last decade that every modern business depends on recognizing and leveraging the strategic value of data.
Big data and extracting meaningful insights
The vast majority of the world's data has been created in the last decade. We entered the zettabyte era and realised that computing power is the most important and innovative form of productivity.
In the 2010s, IT systems have penetrated our daily lives both at personal and business level. As a result, the amount of data has increased exponentially, to 2.5 quintillion bytes (0.0025 zettabytes) of data being created daily in 2020.
Big Data has become increasingly important for business, science, engineering, and our daily lives. It refers to an ever-growing volume of information of various formats that belongs to the same context. But when we say Big Data, how big exactly are we talking?
The true value of Big Data lies in the potential to extract meaningful insights in the process of analysing vast amounts of data while identifying patterns to design smart solutions.
Nevertheless, Big Data presents challenges like how to store and process large scale data. Large data means larger and more complicated distributed data sets. Such data sets are so voluminous that conventional software cannot handle it. Current definitions of Big Data are dependent on the methods and technologies used to collect, store, process, and analyse available data. The most popular definition of Big Data focuses on data itself by differentiating Big Data from “normal” data based on the 7 Vs characteristics:
- Volume - is about the size and amount of Big Data that is being created. It is usually greater than terabytes and petabytes.
- Velocity - is about the speed at which data is being generated and processed. Big Data is often available in real-time.
- Value - is about the importance of insights generated from Big Data. It may also refer to profitability of information that is retrieved from Big Data analysis.
- Variety - is about the diversity and range of different data formats and types (images, text, video, xml, etc.). Big Data technologies evolved with the prime intention to leverage semi-structured and unstructured data, but Big Data can include all types: structured, unstructured, or combinations of structured and unstructured data.
- Variability - is about how the meaning of different types of data is constantly changing when being processed. Big Data often operates on raw data and involves transformations of unstructured data to structured data.
- Veracity - is about making sure that data is accurate and guaranteeing the truthfulness and reliability of data, which refers to data quality and data value.
- Visualisation - is about using charts and graphs to visualise large amounts of complex data in order to both present it and understand it better.
Broadband advancements that powered the decade
We witnessed advances in hardware technology, such as multicore processors going mainstream, and a growing number of mobile devices powered by 4G and later 5G giving us connectivity. 5G wireless networks started being deployed, many with the connections so airtight that it feels like you're in the same room as someone thousands of miles away. These innovations require a steady internet connection to do their jobs, something that in 2009 was not possible, now taken for granted.
The ever-growing speed and bandwidth of the Internet has changed the game for everybody. The data reveal that the world's fastest average connection speeds have increased by a factor of twenty over the past decade.

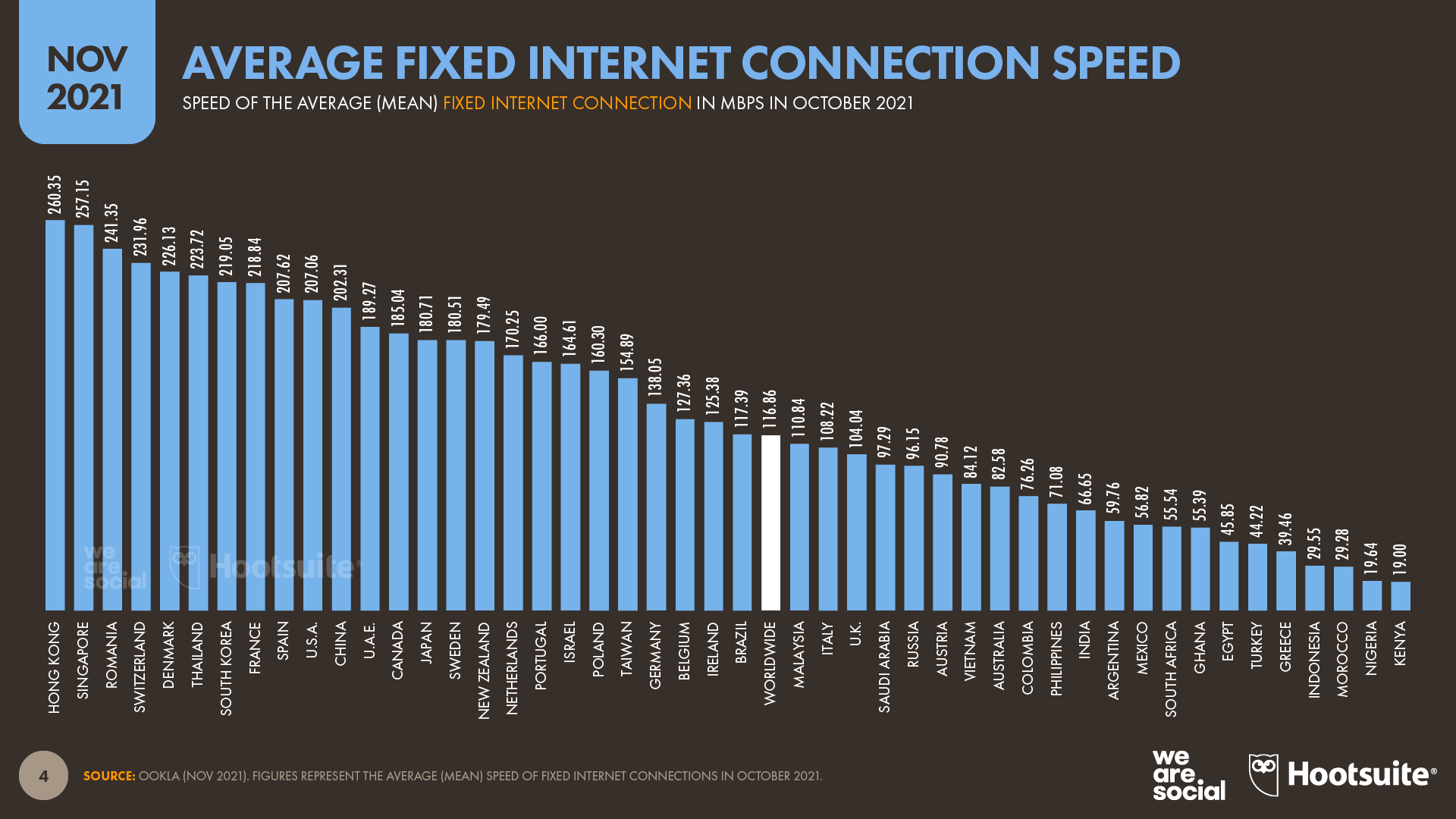
Picture source: datareportal
Faster, more robust broadband speeds became available to more people, which meant that higher quality video files could be delivered online. We have changed how we watch and even think about TV. For a Standard or Premium Netflix plan, a connection speed recommendation is of at least 5 megabits per second for an "HD" quality video. This would clog your entire home internet connection at the beginning of the past decade.
Things have changed and now our homes are filled with connected devices, starting with our mobile phones, laptops, and smart TVs, ending on gaming consoles and a growing number of smart home gadgets. All these use the internet. Every platform requires stream processing and system availability 24/7.
Speed helped make the internet what it has become. It grew from x to x2 and affected how quickly information is transferred. The decade has changed how we connect and collaborate at work. COVID-19 made fast internet connections even more critical. Demand for broadband communication services has soared, with some operators experiencing as much as a 60% increase in internet traffic compared to before the crisis.
Digital transformation
During the last decade, businesses got to know the power of appealing to customers directly by using their digital characteristics and historical data to create better services and products. It spurred a demand for robust and fast IT systems, infrastructure that can be fed with ever-growing volumes of created and consumed data. Fortunately, 2010s finally brought sufficient computing power to process the growing data volumes in a finite time.
To meet the demand, the IT market had to become more diverse. On-prem data solutions became too expensive to manage with growing data volumes. By 2010, the three cloud giants - Amazon, Microsoft, and Google - had all launched their cloud computing platforms.
Cloud technology gained momentum and the world made the transition to cloud-based analytics. Many industries started to rely on rapid analysis of exploding volumes of data at the point of creation and at scale. Technologies like Kubernetes and Docker started to gain traction because they allow cloud-native applications to run anywhere.
Infrastructure as code grew with the expansion of Amazon Web Services and large companies' issues with the scaling of their infrastructure. Having the ability to design, implement, and deploy application infrastructure with IaC software became the best practices that appealed to both software developers and IT infrastructure administrators.
This cloud infrastructure allows for real-time processing of Big Data. It can take huge “blasts” of data from intensive systems and interpret it in real-time. Another common relationship between Big Data and Cloud Computing is that the power of the cloud allows Big Data analytics to occur in a fraction of the time it is used.

Stream processing for rapid analytics
Market demand shifted the focus in the industry: it's no longer that important how big your data is, it's much more important how fast you can analyse it and gain insights.
Processing data in a streaming fashion became more popular over the more "traditional" way of batch-processing big data sets available as a whole. Time became one of the main aspects and it needed first-class handling. We had to answer the question: “what's current?”. It might be the last 5 minutes or the last 2 hours. Or maybe the last 256 events?
IT technology responded.
Hadoop's popularity went down because it could not compete with new generation tools like Apache Spark or Apache Flink, supported by replicated message queues (like Kafka) or scalable NoSQL databases (like DynamoDB or Cassandra) for building modern distributed systems.
Stream Processing, a Big Data technology, came to life. It is used to query continuous data streams and detect conditions quickly, within a small time period from the time of receiving the data.
Stream processing technologies
Real-time stream processing has been gaining momentum in recent years. First generation data stream processing engines, such as Apache Spark and Apache Flink, enabled developers to build real time apps.
In the last decade, we saw many production toolkits emerging that allow for computing on data directly as it is produced or received.
- Erlang-inspired Akka toolkit simplified concurrent processing in multicore environments with the actor model.
- Apache Kafka was created as a fast, scalable, and durable alternative to existing solutions for stream processing and asynchronous communication.
- Apache Spark and Apache Flink improved distributed processing of vast amounts of data.
The main selling point of using stream processing applications has become their latency.
Apache Kafka - Kafka is a stream processing platform that ingests huge real-time data feeds and publishes them to subscribers in a distributed manner. The tool allows you to take up the challenge posed by Big Data when broker technologies based on other standards have failed.
Apache Cassandra - Cassandra is used by many companies with large active data sets of online transactional data. It is a NoSQL database that offers fault-tolerance as well as great performance and scalability without sacrificing availability.
Apache Hadoop - a big data analytics system that focuses on data warehousing and data lake use cases. It uses the Hadoop Distributed File System (HDFS) that provides high throughput access to application data and is suitable for applications that have large data sets.
Apache Pulsar - a multi-tenant, high-performance solution for server-to-server messaging. We decided to evaluate Pulsar and compare it with Kafka. You can find our findings here, especially from a ready-for-enterprise point of view.
Apache Spark - is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Apache Flink - a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
How does stream processing work?
Stream applications process messages in real-time to allow the business, or even automated bots, to act immediately. The IT industry was already there and ready for the mass market. Before the 2010s it could take days to process a large amount of data, and in the span of the last decade, the time has shrunk to milliseconds.
Many companies discovered that they don't really have "big data", but they might have several data streams waiting to be leveraged. That's why some people are now talking about fast data instead of the now old-school big data.
It's no longer only stock exchanges who can (and must) afford such systems, where trades and other transactions have to be executed with millisecond latency. Cloud providers offer the whole stack, covering mature tools for orchestrating, scaling, monitoring, and tracing — all in an automated fashion.
Stream processing framework
Stream processing allows applications to respond to new data events at the moment they occur. Insights from data are available faster, often within milliseconds to seconds from the trigger. All businesses can benefit from analytical data, but once that data goes lost, it could be impossible to restore it. Fortunately, there are techniques that allow to prevent the loss of business data - such a technique is e.g. Event Sourcing. Together with event streaming, different parts of an application can coordinate with one another and share data across data centres, clouds, or geolocations.
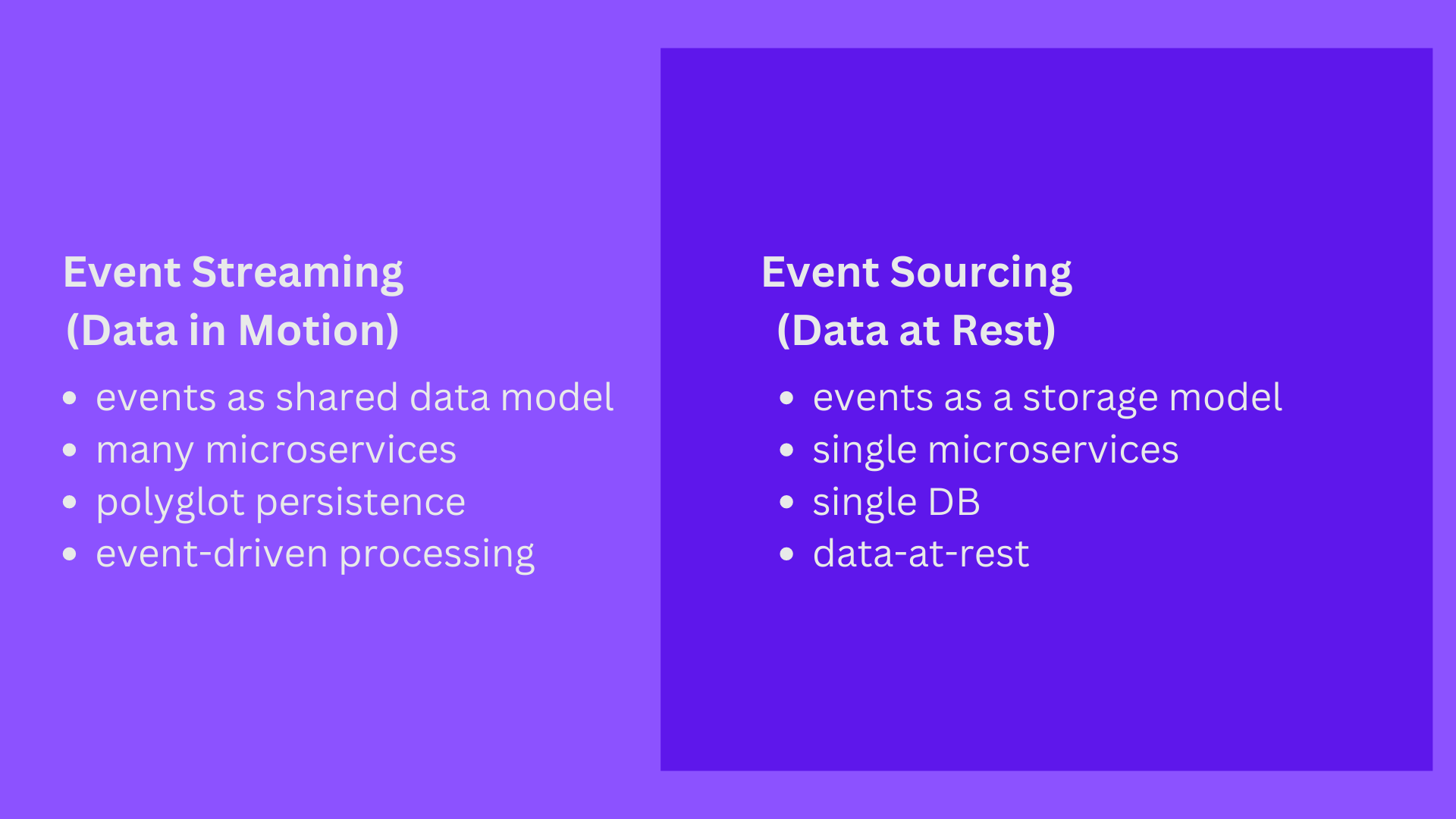
Picture source: Confluent blog

Microservices architecture
From 2010 to now, the rapid spread of digital technologies has contributed to soaring digital transformation budgets. Business started operating digital-first and using technology to create data-driven personalised services.
In order to integrate various Big Data tools and solve IT challenges such as increasing speed, software scalability, and rapid test processes, a component-based microservices approach arrived.
What are microservices?
Microservices architecture has evolved over the past decade to offer a more cohesive, but still granular, approach to software development.
Software that processes a continuous and broad stream of data coming from different sources introduced new architectural challenges. Additionally, the increasing Internet connection bandwidth and availability of cloud providers made the distribution of software not as an installation package, but as a service (SaaS), much more compelling.
Docker and high-performance messaging middleware like Apache Kafka help a lot to meet these requirements.
Microservices stressed the role of DevOps and tools like Docker, Kubernetes, Helm, Terraform, or Prometheus. Instead of moving code from one type of specialist to another (e.g. development, testing, production), cross-functional teams cooperatively build, test, release, monitor, and maintain applications.
It is now easier than ever to:
- Combine software from a couple or even hundreds of relatively small and independent pieces possibly developed by different teams
- Mix different technology stacks (e.g. databases, languages), choosing the best tool for solving a given problem
- Scale horizontally selected parts of the software in response to increased demand
- Implement continuous deployment so the software can be developed with no downtime
Microservices gained popularity with large-scale enterprises including Amazon, Netflix, Twitter, Paypal, and Spotify. What's more, architectural concepts like event sourcing started gaining wide acceptance as a way to consume and manage applications' log data at web-scale.
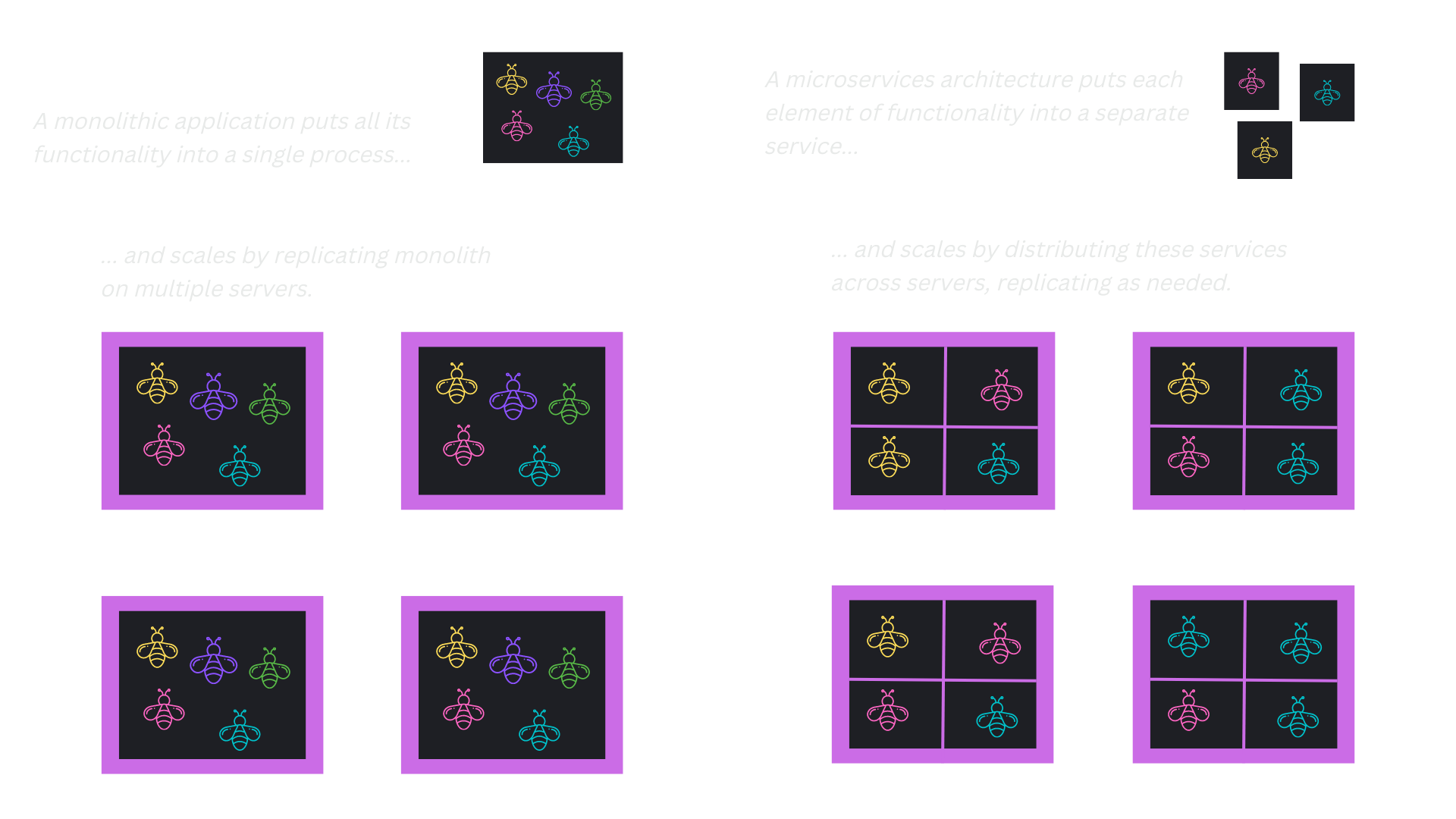
Picture source: Martin Fowler
Business capabilities of microservices
Digitalization and digital transformation affect all businesses, thus for companies that operate on software that is getting too big to deal with (both in terms of the architecture and developer team growth) there is a solution: migrating to microservices architecture.
- Business agility — microservices are easy to scale and are super fault-tolerant if deployed the right way. By making sure you have proper test coverage with Unit tests, Service / API tests, and End to End tests of the integrated systems, your business is safe and sound with this software architecture.
- Software functionalities organised around business needs — microservices allow building products instead of projects. The developers team focuses on building business functionality organised around business capabilities instead of just writing code for “the project”.
- Autonomous and agile developer teams — each team member is responsible for a particular service, which results in building a smart, cross-functional team. There is clear ownership of work with clear division of responsibilities.
- Productivity boost — no spaghetti code! Microservices tackle the problem of productivity and speed by decomposing applications into manageable services that are faster to develop and transparent for developers.
- Future-proof software — technology changes so fast that businesses need to be ready to catch up in order to remain competitive in their markets. Whenever there is a need to change the technology or a programming language, you only need to rewrite a particular service since all microservices are independent of each other.

Most popular programming language for data-intensive applications
Data-intensive applications handle datasets on the scale of multiple terabytes and petabytes. Such use cases were growing in popularity in the last decade as Big Data imposed a lot of challenges like difficulties in data capture, storage, searching, sharing, analysis, and visualisation.
The most dominant programming languages for data-intensive frameworks in the 2010s were Java and Scala. Java is probably the most widely used language in business today. Its Virtual Machine GraalVM and new Garbage Collector ZGC made it an attractive language in almost any domain.
Many developers looking for a “better Java” started exploring Scala and functional programming. Another reason for the rising popularity of Scala was Apache Spark (a data management tool built with Scala). Apache Spark became in fact one of the most popular big data tools in 2015.
Java and Scala programming languages
During the last decade, both Java and Scala were among the most popular server-side languages chosen by software developers. That was also the time of intensive development of JVM - the engine to run applications written in these programming languages.
Java has seen a steady stream of improvements. A bunch of new Java versions were released in the 2010s - from Java 7 to Java 17. Many of the language's new features were influenced by other JVM languages and functional programming, including features such as lambdas, limited local type inference, or switch expressions.
It was also a good decade for the Scala ecosystem. The language evolved from version 2.8.0 to 2.13 and finally into a long-awaited major release: 3.0. Many aspects of the type-system have been changed to be more principled. With new features along, the type-system got less in your way and, for instance, type-inference and overload resolution were much improved.
In the last 10 years, some very promising, modern programming languages like Kotlin, Haskell, or Go, have got new elegant features. But Java and Scala still remain a good choice and in demand programming languages in the context of building data intensive distributed applications.
Benefits of Scala
Scala is a functional, strongly typed, general-purpose programming language. A particular strength of Scala has always been streaming data— type safe, leak-proof, concurrent, and declarative.
The biggest strength of Scala is its flexibility in defining abstractions. There's a number of basic building blocks at our disposal; sometimes defining an abstraction is as simple as using a class, methods, and lambdas; sometimes an implicit parameter has to be used, or an extension method; in rare cases, there's a need to resort to a macro. However, the options are there. Hence, Scala works great when there's a need to navigate a complex domain.
Benefits of Java
Java is a general-purpose computer-programming language that is concurrent, class-based, object-oriented, and specifically designed to develop new software for various platforms. Because of its robustness, ease of use, cross-platform capabilities and security features, it has become a language of choice for many. Java popularity and maturity offers tools and abstractions to model your business and create systems that scale. We build on the solid foundations of Java and Spring ecosystems which allow us to create business-critical software applications. Depending on your business needs, whether it be Scalable Microservices or modular monolith., with Spring Cloud, Micronaut or Quarkus we can deliver applications that will give you an edge over your competition.
Popular programming languages born in the last decade
Here's a look at some new programming languages that have debuted in the past 10 years.
Haskell
Haskell is a general-purpose, statically-typed, purely functional programming language with type inference and lazy evaluation. Designed for teaching, research, and industrial application, Haskell first appeared in 1990 and has pioneered a number of programming language features such as type classes, which enable type-safe operator overloading.
The language is actively developed and worth learning in 2022, as all functional languages are ideal for Big Data and Machine Learning. It has a high learning curve, but offers type safety, highly expressive and concise syntax, and can be used for quick prototyping.
Go
Go, or Golang, is a statically typed, compiled programming language designed at Google to improve programming productivity in an era of multicore, networked machines and large codebases. It was publicly announced in November 2009, and version 1.0 was released in March 2012.
After Go took off at Google and was released to the public, it got really popular as the language of concurrency, which, in turn, helped make it the language of DevOps - particularly in concert with Kubernetes, which also emerged from Google.
New programmers who want to learn Go can quickly understand the language, Go developers can easily read each other's code. However, its internal inconsistencies and limited automation can invite errors.
Kotlin
Kotlin is a cross-platform, statically typed, general-purpose programming language with type inference created by JetBrains. It mainly works on the JVM, but also compiles to JavaScript or native code via LLVM. Kotlin's 1.0 first stable release on February 15, 2016. Google announced it as an official programming language for building Android apps.
Kotlin shares a number of advantages over Java, for example more compact syntax, less boilerplate, richer type system, and no language baggage.

Internet of Things and connectivity
Connected devices
2010s was the advent of a broad range of different internet-connected end-devices capable of communicating with other devices and networks. In 2012, the world saw the first Raspberry Pi, a low cost, credit card-sized computer equipped with an ARM processor that could run Linux.
This small computer and its further versions (the model from 2019 had 1.5 GHz 64-bit quad processor and a 4K HDMI port) enabled the creation of edge devices that made our life smart. IoT deployment started getting more prevalent.
Our environment has become smart in front of our eyes. Connectivity became a priority. In 2009, there were around 900 million connected Internet of Things devices in use around the world, according to figures from Statista. The number of IoT devices worldwide is forecast to almost triple from 9.7 billion in 2020 to more than 29 billion IoT devices in 2030.
Elon Musk has launched satellites into orbit to deliver high-speed broadband internet to as many people as possible. Starlink brought internet connections to areas of the globe where connectivity has typically been a challenge. We saw almost 60% of the global population becoming internet users at the end of the decade, when in 2010, this number was lower than 25%.
Wireless connectivity vs security
4G and 5G wireless technology was invented and delivered higher data speeds, low latency, and better network capacity. More users got better user experience with their smartphones, wearables, sensors and other smart devices.
But with the ease of usability of connectedness comes a price: those items are more vulnerable to hacking attempts. In the 2010s, the rapid evolution and utilisation of IoT technologies has raised security concerns and created a feeling of uncertainty among IoT adopters. In 2017, an 11-year-old boy showed everyone how easy it is to hack IoT devices while using Raspberry Pi and his laptop to scan devices via bluetooth:
“Most internet-connected things have Bluetooth functionality ... I basically showed how I could connect to it, and send commands to it, by recording audio and playing the light.” [Source]
IoT security challenges come mostly from the lack of computational capacity for efficient built-in security in end-devices, insufficient testing and updating, and poor access control in IoT systems. Nowadays, there is a better understanding of the topic from the software engineers and innovators. At the same time also the end users are taught ways to solve IoT vulnerabilities and protect their own IoT devices.
IoT sensors and smart devices use cases
Big data and IoT go hand in hand and now the market has a good number of IoT devices that have been developed with the aim of producing decent amounts of data. Businesses realised that massive quantities of uninterrupted data transmissions the IoT involves could be processed at the edge, effectively minimising the latency in data transfer, reducing IT costs, [and] saving network bandwidth.
Perhaps the most important application of the IoT has been in industrial and logistical fields. Modern e-commerce companies would not be able to offer even a quarter of their services without the Internet of Things powering their methods.
Sensors play an important role in creating solutions using IoT. A sensor is a device that measures physical input from its environment and converts it into data that can be interpreted by either a human or a machine. Modern sensors find their wide usage in a variety of applications such as robotics, navigation, automation, remote sensing, underwater imaging, etc. Remote Sensing is one of favourite data science and Machine Learning use case scenarios explored by our ML engineers.
In simple words, remote sensing is a process of gathering information regarding some objects or phenomena without touching them. Concerning the Earth, it's related to acquiring data by utilising satellites, radars, unmanned aerial vehicles, various sensors, and more.

We need to go Deep Learning
Major AI developments over the last decade focused on a type of machine learning called deep learning. It imitates the way human neurons work. For example, a computer might be looking at numbers of videos of cats to learn to identify what a cat looks like.
In 2012, Google's Artificial brain learned exactly that to find cat videos.
In 2014, Facebook developed DeepFace, an algorithm capable of recognizing or verifying individuals in photographs with the same accuracy as humans. All thanks to Ian Goodfellow's creation: a powerful AI tool, generative adversarial network (GAN) that gave machines the power of imagination and creation.
Also in 2014, Google created a computer program with its own neural network that learned to play the abstract board game Go, which is known for requiring sharp intellect and intuition. AlphaGo's deep learning model learned how to play and in 2015, it defeated the European Go champion Fan Hui, a 2-dan (out of 9 dan possible) professional, five to zero.
In 2017, the Transformers model came to life, a novel neural network architecture for language understanding. This NLP model has truly changed the way we work with text data.
And finally, in 2017, 2018, and 2019, we saw GPT 1, 2, and 3 used to create articles, poetry, stories, news reports, and dialogue.
Intensive development of Deep Learning was possible due to how open ML frameworks were and how relatively easy it was to obtain quality information on the subject.
First of all, the most popular machine learning library used for applications such as computer vision and natural language processing is PyTorch - an open-source tool.
Also Tensorflow, which got a huge update in 2019 (dynamic graphs), is an open source artificial intelligence library, using data flow graphs to build models.
Additionally, AI Framework Interoperability was possible too because Facebook, Microsoft, AWS, Nvidia, Qualcomm, Intel, and Huawei developed the Open Neural Network Exchange (ONNX), an open format for representing deep learning models.
On the hardware side, graphic cards for high-end computer games worked wonderfully in ML use cases. Deep learning is a field with intense computational requirements, and a choice of GPU fundamentally determines deep learning experience.
NVIDIA graphic cards are equipped with specialised processors with dedicated memory to perform floating-point operations, ideal for neural network simulations.
AI 101: What are Deep Learning and Machine Learning?
You can boil many AI innovations down to two concepts: machine learning and deep learning. These terms related to AI are often used interchangeably, but they are not the same thing. So let's introduce some basics of AI terminology.
Machine Learning
After Prof. Youshua Bengio, ML is a part of research on artificial intelligence seeking to provide knowledge to computers through data, observations, and interacting with the world. It is an application of AI and at its most basic level, it is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world — Nvidia.
Deep Learning
After Investopedia, it is the subset of machine learning composed of algorithms that permit software to train itself to perform tasks, like speech and image recognition, by exposing multilayered neural networks to vast amounts of data.
TL;DR: all deep learning is machine learning, but not all machine learning is deep learning. It is so useful because it mimics the behaviour of a human brain, while ML can only use past data to predict what is going to happen in the future.
Modern deep learning era
Deep learning isn't a concept that came to life in the 2010s, but 2010s can be seen as a modern deep learning era - the term was first used in the 1980s. It is extremely beneficial to data scientists who are tasked with collecting, analysing, and interpreting large amounts of data. Deep learning's usefulness lies in recognizing patterns: all kinds of patterns in fact, whether in images, video, or audio.
Deep Learning has appeared increasingly often in the news over the recent years. You may have heard about some of its use cases — more effective face recognition, self-driving cars, or paintings generated by computers. Fun fact: in 2018, someone paid $432K for art generated by an open-source neural network. Now, in 2022, things escalated to the point when we got DALL·E and DALL·E 2, the AI systems that can render text into realistic images and art. Digital artists who want to try their hand at making AI-generated work got an amazing tool to play with and flooded the internet with imagery imagined by AI.


A first art generated by AI. Picture source: Christies.com
Curious what working on a specific type of machine learning tasks may look like? Follow the full set of steps from finding the necessary data, all the way to storing our evaluated machine learning model for later. This is not a detailed tutorial, or some sort of machine learning mini-course: it simply serves as an exploration of a use case.

Ethical AI
In the late 2010s, it became clear that we need to be able to understand the decisions made by AI. In many cases, it was not even possible to understand why the algorithm made a specific decision.
Artificially intelligent machines that may either match or supersede human capabilities pose a big challenge to humanity's traditional self-understanding as the only beings with the highest moral status in the world. Enterprises making huge advancements in the artificial intelligence landscape were struggling to explain the decision-making process of neural networks.
We realised that AI models should not be black boxes anymore. Google came up with the concept of Explainable AI, a service that sheds light on how machine learning models make decisions. It promotes the approach where the knowledge of how the algorithm was trained and what set of parameters was used to achieve a given result is traceable.
Outcomes of machine learning models have to be clear, repeatable, and ethical. At the dawn of the decade, we even saw private blockchain-powered AI solutions considered as a solution for AI stakeholders to achieve transparency and trust. Transparent technologies are needed to play a prominent role in democratising AI.
Why does explainable AI (XAI) matter?
The importance of understanding the AI process and ensuring its accountability is essential. Explainable AI aims to assist human researchers in understanding algorithms such as Deep Learning and neural networks. Machine Learning modelling has always been viewed as a black box that cannot be understood. Neural networks used for deep learning are the most difficult for humans to comprehend. Biassed data are commonly associated largely with race, gender, age or location and are considered risky in preparing AI models. In addition, the performance of AI models could drift due to differences in training and production data.
Ethics in AI is important, and ethical AI aims to ensure that AI projects respect human rights without causing harm to others. It often includes responsibilities and liability, also in cases involving self-driving car accidents.
XAI also addresses some practical and common use cases. Let's take a look at Github Copilot and the IT industry. Copilot is an AI powered pair programming tool developed by Github. It can be used by every developer to generate code for their projects. It's trained on the open source code available publicly. By analysing millions of lines of code it suggests methods and algorithms and creates new lines of code for new projects. It's up to developers if they use, change or reject suggestions. Sounds great, nevertheless many open source developers openly ask whether using Copilot is legal or ethical. Is it ok to use open source projects' source code to train machines to create more code -- something the original developers never envisioned nor intended.

The future is decentralised
Because the digital transformation movement accelerated during the last decade, now we are living in an increasingly interconnected world. Cloud computing brought savings, automation, and scale to many businesses. But when a big cloud provider like AWS experiences an outage, the black-out is affecting businesses of all shapes and sizes.
The issues connected with centralised IT environments reveal the need for decentralised services that are scalable, reliable, and transparent. The future is decentralised. There are disruptive technologies that can introduce trust, accountability, and transparency.
- Enterprises more often use private blockchain to build multi-party business applications with high scalability within a trusted environment.
- Edge computing is flourishing, computing and processing is happening soundly closer to the end user.
- Even Machine Learning computations can be done via a smartphone with new M1 processors from Apple.
- On a global level, people want their privacy to be respected and want to be back in control.
We need to build new information systems that don't rely on any central authorities and data middlemen. There are quite a few technologies already that could power a revolution in decentralised information processing. These are: CRDT, multi-cloud, or private blockchain.
How will the future unfold? Let's shape it together!

Use Cases


eBay
Over the last two decades, eBay collected a volume of 20 petabytes of data. Until recently, the data was maintained in a third-party proprietary warehouse platform. The platform gives access to analytical data for thousands of their specialists. eBay decided to move the data into an in-house solution based on open-source tools. The data landed in Hadoop HDFS accessed by Spark. On top of that, a custom SQL engine was built with the use of Apache Ivy and Delta Lake. Existing users can still access their data using SQL.
By eliminating vendor dependency, this migration puts eBay in full control of its innovation, preparing users for the future of analytics. Some of the biggest wins include:
- A highly resilient analytics data platform modernised across the tech stack;
- An open source solution with full flexibility over features, supporting tools and operations;
- No vendor dependency or constraints to the platform's growth and innovation.
This monumental migration not only resulted in significant cost savings, but also helped drive eBay's renewed tech-led reimagination strategy.
Key Drivers
Key factors that influenced this move were cost, innovation, and more control over eBay's tech journey. The vendor system posed constraints on eBay's scope of expansion and became increasingly expensive. Simultaneously, eBay's technology stack was undergoing a transformation. With a growing focus on data governance, platform reliability, and availability coupled with the rapidly evolving data security landscape, it was imperative for eBay to have full control of its technological innovation.
Technologies:
Apache SparkApache Hadoop HDFSApache IvyDelta Lake
For running a company like LinkedIn, an efficient search engine is a crucial part. To search through petabytes of data in milliseconds, several Lucene indexes were built. Refreshing indices is heavily time and resource-consuming. Back in 2014, a solution based on Hadoop was built, but due to the exponentially growing volume of data, index build time became unsatisfactory. So recently, the index generating infrastructure was updated to leverage Spark features. By distributing index generation and merging into one index with Spark, a significant speed boost was achieved.
Technologies:
Apache Hadoop HDFSApache Hadoop YARNApache SparkPresto
Activision
Call of Duty with Apache Kafka
Activision leverages Apache Kafka for managing player game states in real time. For such games, it is crucial to handle various information in milliseconds so players can enjoy a smooth gameplay experience. Activision has over 1000 topics in their Kafka Cluster and they handle between 10k and 100k messages per second. Various information is being sent, including gameplay stats like shooting events and death location. This podcast shows how Activision deals with ingesting huge amounts of data, what the backend of their massive distributed system looks like, and the automated services involved for collecting data from each pipeline.
Technologies:
Apache Kafka
Uber
Uber used data science to reinvent transportation
Data is very important for Uber. They gather information about all rides, car requests, they even track drivers going through the city without passengers to know the traffic patterns. That data is later leveraged to determine the prices, how long it will take for the driver to arrive, and where to position the car within the city. On the product front, Uber's data team is behind all the predictive models powering the ride sharing cab service, making the company the leader in the industry.
Technologies:
Apache Kafka
FAIR
Facebook Artificial Intelligence Research (FAIR) seeks to understand and develop systems with human-level intelligence and bring the world closer together by advancing AI.
With this particular research, Facebook takes a big step toward reducing the data bottleneck in AI. With DINO, you do not have to show a computer as much labelled data anymore before it develops a basic sense of visual meaning. DINO trains a student network by matching the output of a teacher network over different views of the same image. It means that the need for human annotation is removed and the network can be applied to larger sets, train faster, and scale.
Technologies:
Apache Kafka

