What does Kafka's exactly-once processing really mean?
Kafka’s 0.11 release brings a new major feature: Kafka exactly once semantics. If you haven’t heard about it yet, Neha Narkhede, co-creator of Kafka, wrote a post which introduces the new features, and gives some background.
This announcement caused a stir in the community, with some claiming that exactly-once is not mathematically possible. Jay Kreps wrote a follow-up post with more technical details. Plus, if you’re really curious, there’s also a detailed design document available.
However, as there’s still some confusion as to what exactly-once means in Kafka’s context, I’d like to analyse how you can construct a Kafka exactly once pipeline, with an emphasis on where the new features come into play, what kind of guarantees you get, and more importantly, what guarantees you don’t get.
Some of the discussions focused on whether Kafka guarantees exactly-once processing or delivery. I’m not sure if there are precise definitions of either; but, to avoid ambiguity, I would say that Kafka provides an observably exactly-once guarantee, if we take into account only Kafka-related side-effects.
Using the features of 0.11, it is possible to create a pipeline where, at each stage, the result of processing of each message will be observed exactly-once, as far as Kafka is concerned. This includes the producer (through which the data enters the Kafka pipeline), through possibly many intermediate Kafka-streams-based steps, to the consumer (where the data leaves the Kafka pipeline).
The features which make the above possible are:
idempotent producers (introduced in 0.11)
transactions across partitions (introduced in 0.11)
Kafka-based offset storage (introduced in 0.8.1.1)
Let’s see which of these features are useful at which stage of a Kafka exactly once processing pipeline.

Producer
On the producer side, the crucial feature is idempotency. To prevent a message from being processed multiple times, we first need to make sure that it is persisted to the Kafka topic only once. With idempotency turned on, each producer gets a unique id (the PID), and each message is sent together with a sequence number. When either the broker or the connection fails, and the producer retries the message sent, it will only be accepted if the sequence number of that message is 1 more than the one last seen.
Note, however, that if the producer fails and restarts, it will get a new Pid (or the same one, but with a new epoch number, when a TransactionalId is specified in the config). Hence, the idempotency guarantees only span a single producer session. We might still get duplicates, depending on where the producer gets the data from. If it’s e.g. an HTTP endpoint accessed by a mobile client, in case of failure the mobile client will retry sending, and Kafka won’t prevent the duplicate from being persisted. Or, if we are transferring data from another system to Kafka, we might get duplicates, depending on how we determine the “starting point” from which to read the data from the source system.
Hence, in some cases, we might need an additional deduplication component. In others, for example when transferring data from another storage system, Kafka Connect might be worth looking at: it provides a lot of connectors out-of-the-box.
Pipeline stages
Now that we have the data in Kafka, what about processing it? There’s a lot that we can do with data without leaving Kafka, thanks to Kafka Streams. Apart from simple mapping & filtering, we can also aggregate, compute queryable projections, window the data based on event or processing time, and so on. In the process, the data goes through multiple Kafka topics, and multiple processing stages.
So, how to make sure that in each stage, we observe each message as being processed exactly once?
Here the new transactions feature comes in. Using it, it’s possible to atomically write data to multiple topics and partitions along with offsets of consumed messages. If we take a closer look at what a single processing step does, it reads data from one or more source topics, performs a computation, and writes the data back to one or more target topics. And we can capture this as an atomic Kafka transaction unit: writing to target topics, and storing the offsets in source topics.
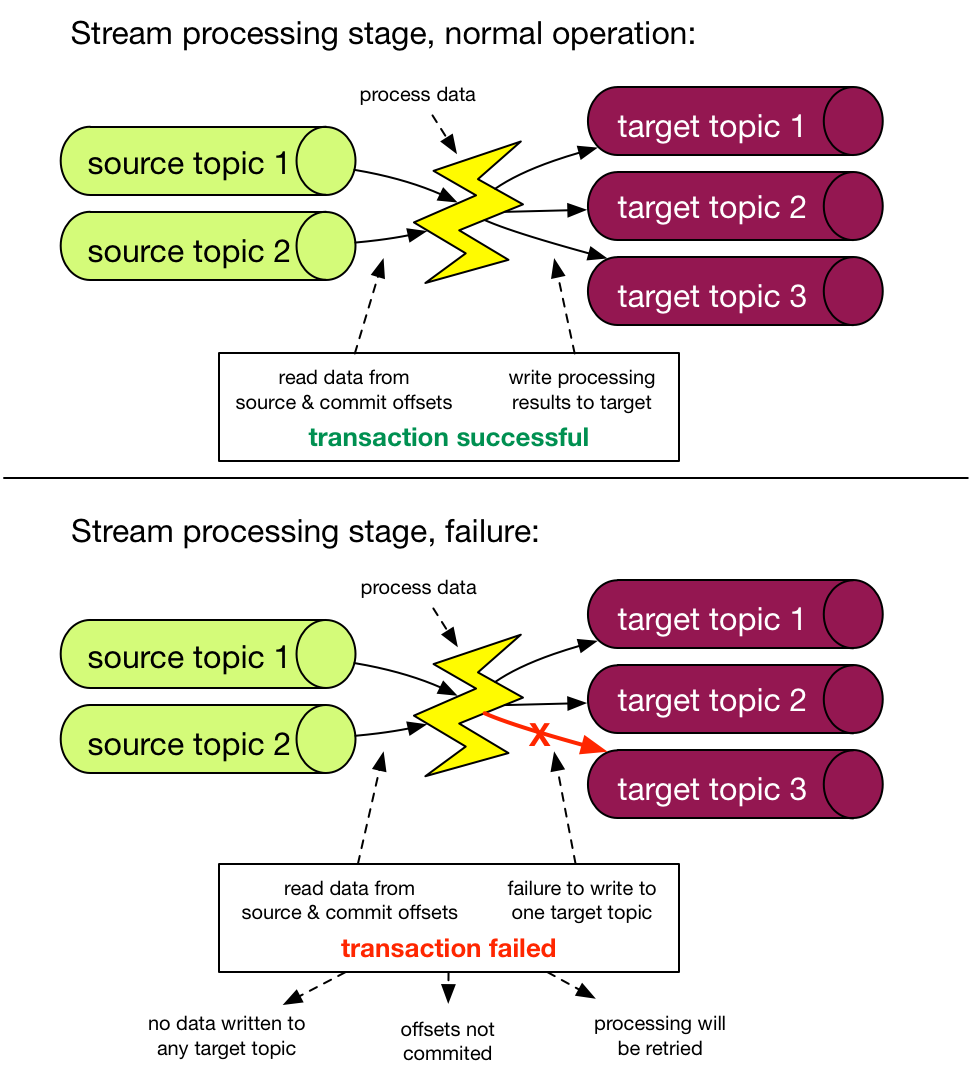
When the exactly-once processing guarantee configuration is set on a Kafka streams application, it will use the transactions transparently behind the scenes; there are no changes in how you use the API to create a data processing pipeline.
We all know that transactions are hard, especially distributed ones. So, how come they work in a distributed system such as Kafka? The key insight here is that we are working within a closed system - that is the transaction spans only Kafka topics/partitions.
Consumer
Finally, we will probably need to get the data out of Kafka. How to make sure this is done exactly-once? Here it’s possible provided that the consumer is transactional, i.e. if we can store the result of processing of a given message, along with its offset, together as an atomic unit in the target system. Again, Kafka Connect might be useful here.
Alternatively, this will also work if the sink is idempotent. In fact, if our processing stages are idempotent, we don’t really need any of the additional Kafka exactly once features: at-least-once is good enough.
Side-effects
If a failure occurs at any of the above described steps, a message might be processed many times - here the at-least-once guarantee is preserved. Because of that, if any of the stages or the consumer has side-effects, they might be executed multiple times. For example, if you have a simple println in your consumer, or streams stage, you might see some messages processed twice. The same applies to sending e-mails, or calling any kind of http endpoints.
However, the messages will only be processed multiple times internally. If there are no extra side-effects, the observable effect - which in the case of Kafka Streams is what gets written to the target topics of each stage - will be as if each message was processed exactly once.
Summary
If we take the meaning of exactly-once delivery/processing literally, Kafka gives neither: messages might be delivered to each processing stage/consumer multiple times, as well as processed by a stream’s stage multiple (at-least-once) times. But when using idempotent sends and transactions, we can make sure that observably we achieve exactly-once: the result of processing each message will end up in the target stream only once. All that with a single configuration change.