Kafka with selective acknowledgments (kmq) performance & latency benchmark
When receiving messages from Apache Kafka, it's only possible to acknowledge the processing of all messages up to a given offset. Thanks to this mechanism, if anything goes wrong and our processing component goes down, after a restart it will start processing from the last committed offset.
However, in some cases what you really need is selective message acknowledgment, as in "traditional" message queues such as RabbitMQ or ActiveMQ. That is, we'd like to acknowledge processing of messages individually, one by one. This might be useful for example when integrating with external systems, where each message corresponds to an external call and might fail.
If a message isn't acknowledged for a configured period of time, it is re-delivered and the processing is retried. That's exactly how Amazon SQS works.
Such a behavior can also be implemented on top of Kafka, and that's what kmq does. It uses an additional markers topic, which is needed to track for which messages the processing has started and ended. For a detailed description of kmq's architecture see this blog post.
Given the usage of an additional topic, how does this impact message processing performance? Let's find out!
We'll be comparing performance of a message processing component written using plain Kafka consumers/producers versus one written using kmq.
Test configuration
The tests were run on AWS, using a 3-node Kafka cluster, consisting of m4.2xlarge servers (8 CPUs, 32GiB RAM) with 100GB general purpose SSDs (gp2) for storage. All the Kafka nodes were in a single region and availability zone. While for a production setup it would be wiser to spread the cluster nodes across different availability zones, here we want to minimize the impact of network overhead.
Additionally, for each test there was a number of sender and receiver nodes which, probably unsurprisingly, were either sending or receiving messages to/from the Kafka cluster, using plain Kafka or kmq and a varying number of threads. The tests used from 1 to 8 sender/receiver nodes, and from 1 to 25 threads.
All of these resources were automatically configured using Ansible (thanks to Grzegorz Kocur for setting this up!) and the mqperf test harness.
Test data
Messages were sent in batches of 10, each message containing 100 bytes of data.
Depending on a specific test, each thread was sending from 0.5 to 1 million messages (hence the total number of messages processed varied depending on the number of threads and nodes used).
The Kafka topics used from 64 to 160 partitions (so that each thread had at least one partition assigned).
Sender/receiver code and Kafka configuration
As we are aiming for guaranteed message delivery, both when using plain Kafka and kmq, the Kafka broker was configured to guarantee that no messages can be lost when sending:
- the topics were created with a
replication-factorof3 - Kafka was configured with
min.insync.replicas=2 - the producer used for sending messages was created with
acksset toall(-1)
This way, to successfully send a batch of messages, they had to be replicated to all three brokers. The send call doesn't complete until all brokers acknowledged that the message is written.
The sending code is identical both for the plain Kafka (KafkaMq.scala) and kmq (KmqMq.scala) scenarios. Given a batch of messages, each of them is passed to a Producer, and then we are waiting for each send to complete (which guarantees that the message is replicated).
The receiving code is different; when using plain Kafka (KafkaMq.scala), we are receiving batches of messages from a Consumer, returning them to the caller. Message acknowledgments are periodical: each second, we are committing the highest acknowledged offset so far.
With kmq (KmqMq.scala), we are using the KmqClient class, which exposes two methods: nextBatch and processed. The first one reads a batch of data from Kafka, writes a start marker to the special markers topic, and returns the messages to the caller. The processed method is used to acknowledge the processing of a batch of messages, by writing the end marker to the markers topic.
The kafka acknowledgment behavior is the crucial difference between plain apache Kafka consumers and kmq: with kmq, the acknowledgments aren't periodical, but done after each batch, and they involve writing to a topic.
Test results
Test results were aggregated using Prometheus and visualized using Grafana. Let's see how the two implementations compare.
First, let's look at the performance of plain apache Kafka consumers/producers (with message replication guaranteed on send as described above):
The "sent" series isn't visible as it's almost identical to the "received" series! Hence, messages are always processed as fast as they are being sent; sending is the limiting factor. A single node using a single thread can process about 2 500 messages per second. When using 6 sending nodes and 6 receiving nodes, with 25 threads each, we get up to 62 500 messages per second. Note that adding more nodes doesn't improve the performance, so that's probably the maximum for this setup.
Now let's do the same, but using kmq:
The graph looks very similar! Again, the number of messages sent and received per second is almost identical; a single node with a single thread achieves the same 2 500 messages per second, and 6 sending/receiving nodes with 25 threads achieve 61 300 messages per second. Same as before, the rate at which messages are sent seems to be the limiting factor.
Hence, in the test setup as above, kmq has the same performance as plain Kafka consumers!
If you are curious, here's an example Graphana dashboard snapshot, for the kmq/6 nodes/25 threads case:
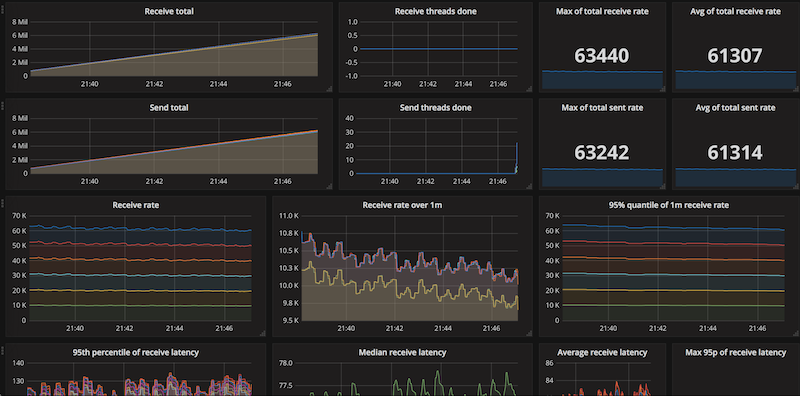
But how is that possible, as receiving messages using kmq is so much complex? After all, it involves sending the start markers, and waiting until the sends complete! Part of the answer might lie in batching: when receiving messages, the size of the batches is controlled by Apache Kafka; these can be large, which allows faster processing, while when sending, we are always limiting the batches to 10.
Send messages faster?
What happens when we send messages faster, without the requirement for waiting for messages to be replicated (setting acks to 1 when creating the producer)?
It turns out that both with plain Apache Kafka and kmq, 4 nodes with 25 threads process about 314 000 messages per second. Again, no difference between plain Kafka and kmq. It would seem that the limiting factor here is the rate at which messages are replicated across Apache Kafka brokers (although we don't require messages to be acknowledged by all brokers for a send to complete, they are still replicated to all 3 nodes).
What if we try to eliminate sending completely, by running the receiver code on a topic already populated with messages? With plain Kafka, the messages are processed blaizingly fast - so fast, that it's hard to get a stable measurement, but the rates are about 1.5 million messages per second. With kmq, the rates reach up to 800 thousand. However, the measurements vary widely: the tests usually start very slowly (at about 10k messages/second), to peak at 800k and then slowly wind down:
In this scenario, kmq turns out to be about 2x slower. However, keep in mind that in real-world use-cases, you would normally want to process messages "on-line", as they are sent (with sends being the limiting factor).
Latency
Performance looks good, what about latency? The measurements here are inherently imprecise, as we are comparing clocks of two different servers (sender and receiver nodes are distinct). Even though both are running the ntp daemon, there might be inaccuracies, so keep that in mind.
When using plain Apache Kafka consumers/producers, the latency between message send and receive is always either 47 or 48 milliseconds.
With kmq, we sometimes get higher values: 48ms for all scenarios between 1 node/1 thread and 4 nodes/5 threads, 69 milliseconds when using 2 nodes/25 threads, up to 131ms when using 6 nodes/25 threads. That's because of the additional work that needs to be done when receiving.
What if messages are dropped
The reason why you would use kmq over plain Kafka is because unacknowledged messages will be re-delivered. How do dropped messages impact our performance tests? Redelivery can be expensive, as it involves a seek in the Apache Kafka topic.
We'll be looking at a very bad scenario, where 50% of the messages are dropped at random. With such a setup, we would expect to receive about twice as many messages as we have sent (as we are also dropping 50% of the re-delivered messages, and so on).
Here's the receive rate graph for this setup (and the Graphana snapshot, if you are interested):
As you can see, when the messages stop being sent (that's when the rate starts dropping sharply), we get a nice declining exponential curve as expected.
Summing up
It turns out that even though kmq needs to do significant additional work when receiving messages (in contrast to a plain Kafka consumer), the performance is comparable when sending and receiving messages at the same time! The limiting factor is sending messages reliably, which involves waiting for send confirmations on the producer side, and replicating messages on the broker side.
We have seen that in the reliable send&receive scenario, you can expect about 60k messages per second sent/received both with plain Apache Kafka and kmq, with latencies between 48ms and 131ms.
Kmq is open-source and available on GitHub. Please star if you find the project interesting!