Benchmarking akka-stream-kafka
As the reactive-kafka library got more and more popular, Akka Team has joined in to make it an official part of the ecosystem (and renamed the lib to akka-stream-kafka). This collaboration resulted in a groundbreaking recent 0.11 release, which brings new API and documentation. Read here for more details.
One of the major factors taken into account was performance. The new API got reviewed and tested in order to bring satisfying throughput for most important scenarios. Let’s see what are those scenarios and how the library performs. We will also discuss some internal tweaks which brought dramatic improvements for some cases.
Test scenarios
All the benchmarks have been executed on a docker image deployed to EC2 (m4.large) using local connection to Apache Kafka 0.10.0.1. With containers we can quickly re-deploy different versions of the library and always verify it on referential hardware using a few simple docker commands. Here are chosen test scenarios:
Plain consumer
The simplest consumer scenario - a single Source consuming from Kafka topic without committing. We compared two variants:
- a recursive loop reading from the topic with vanilla Kafka client and immediately discarding messages
- a reactive stream obtained with
Consumer.plainSource()connected to aSink.ignore
At-least-once-delivery
This scenario requires committing messages after processing. We compared:
- a recursive loop reading from Kafka topic with vanilla Kafka client and committing with
consumer.commitAsync()in batches - a reactive stream obtained with
Consumer.committableSource(), committing in batches withmapAsync

At-most-once-delivery
This scenario commits each message before processing, ensuring that no message gets delivered twice, thus allowing some messages to be lost in favor of non-repetition guarantees. This is the slowest stream, because it commits every single message. We compared two implementations:
- A
forloop reading elements with vanilla Kafka client and callingcommitAsync()on each message, blocking further reading until commit gets acknowledged. This is a primitive way of achieving a sort of backpressure on commit. - A reactive stream obtained with
Consumer.committableSource(), committing each message withmapAsync

Producer
The last measurement was taken from a scenario where we wanted to put messages in Kafka as fast as possible. Compared implementations are:
- A
forloop callingproducer.send()without waiting for confirmation - A reactive stream sending messages to a
Producer.plainSink()

It’s important to mention that above scenarios are not fully equivalent. The for loop writes to Kafka as fast as it’s permitted by client's internal buffer size. The reactive scenario is backpressured by the sink actually waiting for ACK of each write. A parallelism factor of 100 has been applied to allow up to 100 simultaneous producer.send() calls. This factor can be tuned in akka-stream-kafka configuration file.
The evolution
The first tested release (0.11-M4) was mostly about the new API, without particular attention on the performance. The numbers were far from satisfying. Further development focused strongly on spotting and repairing the bottlenecks. Here are some important improvements that appeared in next releases:
Consumer loop
Kafka consumer API is in many ways incompatible with the reactive paradigm. The main idea is to keep a loop which calls a blocking consumer.poll() function. This function either returns some data or returns after a defined timeout. What’s more important, the poll() call is also responsible for executing the commitAsync() callback which wouldn’t happen without it. This callback is performed on the same thread which called poll(). The consumer also offers pause() and resume() functions. These functions allow marking that our poll() calls should ignore particular topics/partitions. They come in handy when we called consumerAsync() and we need to keep pinging poll() in order to execute the callback but we don’t want to poll any more elements. This whole consuming flow is required to manage backpressure - one of the most important aspects of reactive streams. The main idea is to respect the demand from downstream and get elements from Kafka only when needed.
In order to improve performance, internal consumer actor now calls consumer.poll(0) multiple times with short 10 μs delay followed by 1 poll(1). If no elements are returned, a scheduled self-message will re-trigger the whole loop in the actor. Such approach gives much better results that hanging for longer timeouts on poll(). The scheduled actor self-call has been switched from repeated scheduler.scheduleOnce() to more simplistic and efficient scheduler.schedule().
Producer and async callbacks
The producer actor calls low-level producer.send() and provides a callback. This callback gets executed on the same thread, so executing it directly is against the good practices of akka-stream. Instead, getAsyncCallback() has been leveraged.
Blocking and async boundaries
Due to concurrency model used by plain Kafka API, it is possible that consumer.poll() and producer.send() block. Although we have some control over this blocking (timeouts), it is still possible that these calls hang unexpectedly (mostly when there are connection problems). To avoid this, akka-stream-kafka has to keep the Consumer and Producer stages within isolated Dispatchers. Introducing such boundaries has unavoidable negative impact on overall performance, but it’s a reasonable price to pay for keeping safety and adhering to reactive principles.
The results
The benchmark scenarios that we mentioned before have been executed against the final release and the results look much better. Here are some comparisons of improvements:
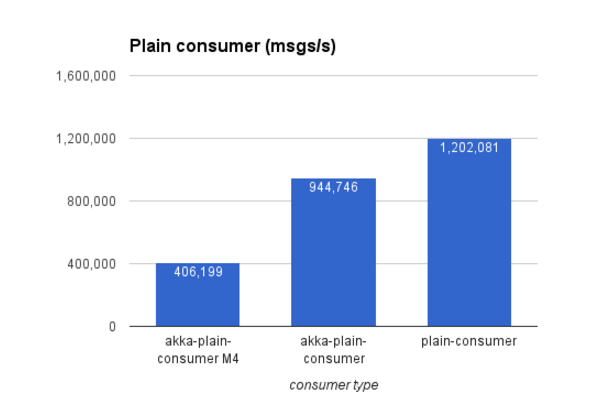
Reactive plain consumer stream: 406,000 msgs/s raised to 944,000 msgs/s
Plain consumer: 1,200,000 msgs/s
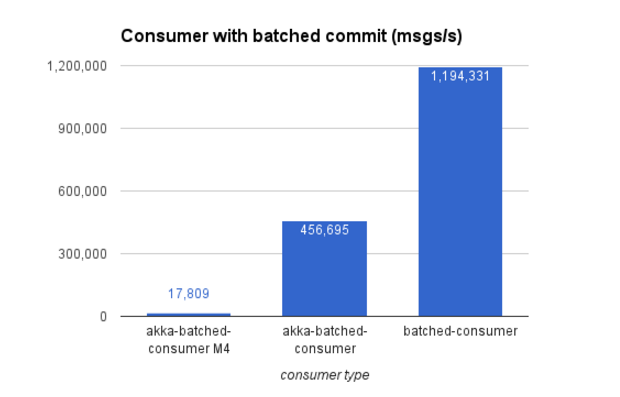
Reactive batched consumer stream (at-least-once-delivery): 17,000 msgs/s raised to 456,000 msgs/s
Plain batched consumer: 1,194,000 msgs/s
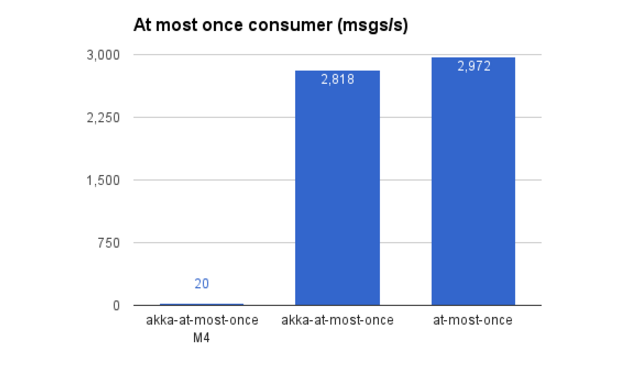
Reactive at-most-once consumer stream: 20 msgs/s (yikes!) raised to 2,800 msgs/s
Plain at-most-once consumer: 2,900 msgs/s
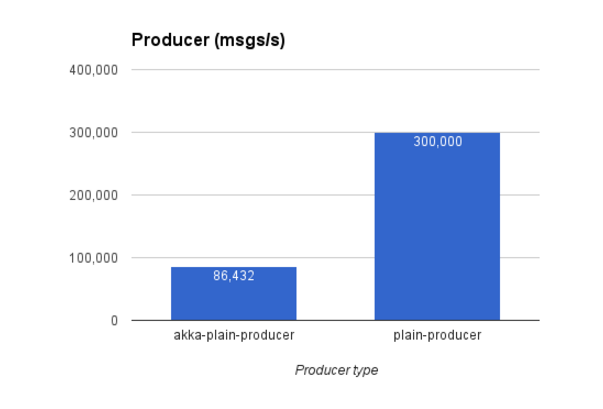
Reactive producer: 86,000 msgs/s (with parallelism = 100)
Plain producer: 300,000 msgs/s
The road ahead
Now that the first major release is out, the team keeps working on adding features and benchmarking more sophisticated scenarios. We are looking for contributors, so don’t hesitate to join us. You can check the sources on github or visit project's gitter channel.