Amazon's SQS performance and latency
It's been a while since we last looked at how fast Amazon SQS is. Did anything change? What kind of performance can you expect from simple AWS queue service (amazon sqs)?
How SQS works
First, a quick refresher (or introduction, if you are not yet familiar with the service) on how SQS works.
Amazon SQS is a message queueing service, meaning that it exposes an API to publish and consume messages. Unlike a publish-subscribe system, a single message should be delivered to a single consumer, even when there are a lot of consumers running concurrently (also known as the competing consumers pattern).
When a message is being received from the system, it is blocked from being visible to other consumers for a given period of time. If the message isn't deleted before this timeout elapses, it will be re-delivered. That way, SQS implements at-least-once delivery.
SQS exposes a HTTP-based interface, but it's much more convenient to use one of Amazon's SDKs to make the requests, such as the Java SDK which we will be using.
While we don't know the details of SQS's implementation, Amazon states that AWS queue data is stored redundantly across multiple servers, making SQS a replicated, reliable message queue.
Testing infrastructure
The tests were run using a number of sender and receiver nodes which were either sending or receiving messages to/from SQS. Each test used from 1 to 12 sender/receiver nodes, and each node was running from 1 to 25 threads.
The sender/receiver nodes were m4.2xlarge EC2 servers (8 CPUs, 32GiB RAM), located in a single region and availability zone.
Test data
Messages were sent and received in batches of 10, each message containing 100 bytes of data.
Depending on a specific test, each thread was sending from 100 000 to 200 000 messages. As there were multiple threads and multiple nodes, the total number of messages in each test varied. For example, with 4 sending nodes, 4 receiving nodes each running 25 threads sending 100k messages, the total number of messages processed was 10 million.
Test code
The sending/receiving code is quite simple, and uses Amazon's Java SDK. You can see the full (short) source in the mqperf project on GitHub. Each thread on each node was either calling the createSender() or createReceiver() methods on startup, and then running the logic in a loop until all the messages have been processed.
What we measured
We were looking at four values in the tests:
- total number of messages sent per second (by all nodes)
- total number of messages received per second
- 95th percentile of message send latency (how fast a message send call completes)
- 95th percentile of message processing latency (how long it takes between sending and receiving a message)
Test results
Single-node
In a one-node setup (1 sender node, 1 receiver node) with one thread SQS can process about 590 msgs/s, with a send latency below 100 ms and processing latency of about 150ms (that's how long it takes for a message to travel through SQS).
By running more threads, we can scale this result:
| Nodes | Threads | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 592 | 592 |
| 1 | 5 | 2 525 | 2 525 |
| 1 | 25 | 8 399 | **6 892** |
| 1 | 50 | **16 982** | 6 789 |
As you can see, while we are able to send more and more messages by increasing the number of threads, the maximum on the receiving side for a single m4.2xlarge node is about 6 800 msgs/s.
Adding nodes
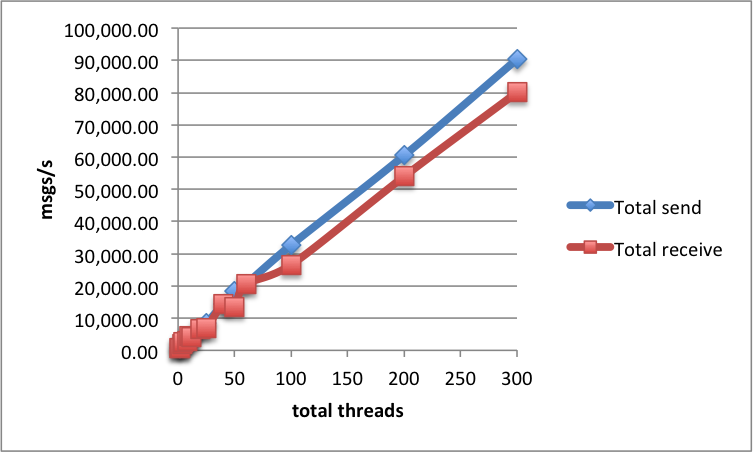
By adding more nodes, we can scale the throughput of SQS almost linearly. Let's look at the test which uses 25 threads:
| Nodes | Threads | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 25 | 8 399 | 6 892 |
| 2 | 25 | 14 424 | 13 313 |
| 4 | 25 | 31 337 | 26 961 |
| 8 | 25 | 60 467 | 53 946 |
| 12 | 25 | **90 361** | **80 069** |
If we graph these values, we get a nice linear throughput increase:
Send latency
In all tests, the send latency remained quite low, around 60ms-70ms. That's how fast the HTTP call to the SQS API completes, giving you a reasonable guarantee that the messages have been sent and replicated across the SQS cluster.
Processing latency
With processing latency - that is, how fast a message is received after sending - we got a much wider array of results. First of all, to check the receive latency, we can only look at tests where messages are sent and received at the same rate - otherwise, the latencies get arbitrarily high.
The lowest values that we have observed were around 130 ms when running a single thread. However, when using 5 threads, the latencies (95th percentile) grew all the way up to over 1 300ms:
| Nodes | Threads | Receive latency |
|---|---|---|
| 1 | 1 | 130 ms |
| 1 | 5 | 257 ms |
| 2 | 1 | 291 ms |
| 2 | 5 | **717 ms** |
| 4 | 1 | 109 ms |
| 4 | 5 | **842 ms** |
| 8 | 1 | 109 ms |
| 8 | 5 | **409 ms** |
| 12 | 1 | 133 ms |
| 12 | 5 | 270 ms |
All the tests results were aggregated using Prometheus and visualized using Grafana (thanks to Grzegorz Kocur for setting this up!).
Here's a snapshot of the dashboard for the 5 threads, 8 sending and 8 received nodes test case:
Conclusion
Amazon SQS offers good performance, with great scalability characteristics. The message send latencies are low, however message processing latencies are less predictable: you might get 100ms, or you might get 1 second.
Comparing to results from 2014, you can notice that while message send throughput is mostly unchanged, messeage receive throughput got up to 50% better. This might be a result of internal improvements, but also an effect of using more modern hardware for the receiver (m4.2xlarge - 8 cores vs m3.large - 2 cores).
For high-volume message processing, remember that while SQS is cheap, it might get expensive when sending large volumes of messages for a long time. At some point, it's certainly worth considering setting up a dedicated broker (shameless plug - maybe consider KMQ, Kafka with redeliveries?).
However except for the constant high-volume case described above, SQS is a great and reliable solution both for small and large applications, which need a task queue or message queue to communicate between their services.
Need to compare different message queueing and data streaming systems? Read more in this article by Adam Warski.