Evaluating persistent, replicated message queues (2017 edition)
Introduction
Message queues are central to many distributed systems and often provide a backbone for asynchronous processing and communication between (micro)services. They are useful in a number of situations; any time we want to execute a task asynchronously, we put the task on a queue and some executor (could be another thread, process or machine) eventually runs it. Or when a stream of events arrives at our system, we want them to be received quickly, and processed asynchronously by other components later.
Depending on the use case, message queues can give various guarantees on message persistence and delivery. For some use-cases, it is enough to have an in-memory, volatile message queue. For others, we want to be sure that once the message send completes, the message is persistently enqueued and will be eventually delivered, despite node or system crashes.
In the following tests we will be looking at queueing systems at the 'safe' side of this spectrum, which try to make sure that messages are not lost by:
- persisting messages to disk
- replicating messages across the network
We will be looking at how many messages per second a given queueing system can process, but also at the processing latency, which is an important factor in systems which should react to new data in near real-time (as is often the case with various event streams). Another important aspect is message send latency, that is how long it takes for a client to be sure a message is persisted in the queueing system. This may directly impact e.g. the latency of http endpoints and end-user experience.
Version history
| 1 August 2017 | Updated the results for Artemis, using memory-mapped journal type and improved JMS test client |
| 18 July 2017 | 2017 edition: updating with new versions; adding latency measurements; adding Artemis and EventStore |
| 4 May 2015 | 2015 edition: updated with new versions, added ActiveMQ; new site |
| 1 July 2014 | original at Adam Warski's blog |
Tested queues
There is a number of open-source messaging projects available, but only some support both persistence and replication. We'll evaluate the performance and characteristics of 7 message queues:
While SQS isn't an open-source messaging system, it matches the persistence and replication requirements and it can be interesting to compare self-hosted solutions with an as-a-service one.
MongoDB isn't a queue of course, but a document-based NoSQL database, however using some of its mechanisms it is very easy to implement a message queue on top of it.
If you know of any other messaging systems which provide durable, replicated queues, let us know!
Queue characteristics
There are three basic operations on a queue which we'll be using:
- sending a message to the queue
- receiving a message from the queue
- acknowledging that a message has been processed
On the sender side, we want to have a guarantee that if a message send call completes successfully, the message will be eventually processed. Of course, we will never get a 100% "guarantee", so we have to accept some scenarios in which messages will be lost, such as a catastrophic failure destroying all of our geographically distributed servers. Still, we want to minimise message loss. That's why:
- messages should survive a restart of the server, that is messages should be persisted to a durable store (hard disk). However, we accept losing messages due to unflushed disk buffers (we do not require
fsyncs to be done for each message). - messages should survive a permanent failure of a server, that is messages should be replicated to other servers. We'll be mostly interested in synchronous replication, that is when the send call can only complete after the data is replicated. Note that this additionally protects from message loss due to hard disk buffers not being flushed. Some systems also offer asynchronous replication, where messages are accepted before being replicated, and thus there's more potential for message loss. We'll make it clear later which systems offer what kind of replication.
On the receiver side, we want to be able to receive a message and then acknowledge that the message was processed successfully. Note that receiving alone should not remove the message from the queue, as the receiver may crash at any time (including right after receiving, before processing). But that could also lead to messages being processed twice (e.g. if the receiver crashes after processing, before acknowledging); hence our queue should support at-least-once delivery.
With at-least-once delivery, message processing should be idempotent, that is processing a message twice shouldn't cause any problems. Once we assume that characteristic, a lot of things are simplified; message acknowledgments can be done asynchronously, as no harm is done if an ack is lost and the message re-delivered. We also don't have to worry about distributed transactions. In fact, no system can provide exactly-once delivery when integrating with external systems (and if it claims otherwise: read the fine print); it's always a choice between at-most-once and at-least-once.
By requiring idempotent processing, the life of the message broker is easier, however, the cost is shifted to writing application code appropriately.
Testing methodology
We'll be performing three measurements during the tests:
- throughput in messages/second: how fast on average the queue is, that is how many messages per second can be sent, and how many messages per second can be received & acknowledged
- 95th percentile of processing latency (over a 1-minute window): how much time (in milliseconds) passes between a message send and a message receive. That is, how fast the broker passes the message from the sender to the receiver
- 95th percentile of send latency (over a 1-minute window): how long it takes for a message send to complete. That's when we are sure that the message is safely persisted in the cluster, and can e.g. respond to our client's http request "message received".
When setting up the queues, our goal is to have 3 identical, replicated nodes running the message queue server, with automatic fail-over.
All sources for the tests are available on GitHub.
Each test run is parametrised by the type of the message queue tested, optional message queue parameters, number of client nodes, number of threads on each client node and message count. A client node is either sending or receiving messages; in the tests we used from 1 to 8 client nodes of each type (there's always the same number of client and receiver nodes), each running from 1 to 25 threads.
Each Sender thread tries to send the given number of messages as fast as possible, in batches of random size between 1 and 10 messages. For some queues, we'll also evaluate larger batches, up to 100 or 1000 messages.
The Receiver tries to receive messages (also in batches of up to 10 messages), and after receiving them, acknowledges their delivery (which should cause the message to be removed from the queue). The test ends when no messages are received for a minute

The queues have to implement the Mq interface. The methods should have the following characteristics:
sendshould be synchronous, that is when it completes, we want to be sure (what sure means exactly may vary) that the messages are sentreceiveshould receive messages from the queue and block them from other clients; if the node crashes, the messages should be returned to the queue and re-deliveredackshould acknowledge delivery and processing of the messages. Acknowledgments can be asynchronous, that is we don't have to be sure that the messages really got deleted.
Server setup
Both the clients, and the messaging servers used m4.2xlarge EC2 instances; each such instance has 8 virtual CPUs, 32GiB of RAM and SSD storage (in some cases additional gp2 disks where used). All instances were started in a single availability zone (eu-west-1). While for production deployments it is certainly better to have the replicas distributed across different locations (in EC2 terminology - different availability zones), but as the aim of the test was to measure performance, a single availability zone was used to minimise the effects of network latency as much as possible.
The servers were provisioned automatically using Ansible. All of the playbooks are available in the github repository, hence the tests should be reproducible with minimal effort.
Test results were aggregated using Prometheus and visualized using Grafana. We'll see some dashboard snapshots with specific results later.
Mongo
| Version | server 3.4.6, java driver 3.4.2 |
| Replication | configurable, asynchronous & synchronous |
Mongo has two main features which make it possible to easily implement a durable, replicated message queue on top of it: very simple replication setup (we'll be using a 3-node replica set), and various document-level atomic operations, like find-and-modify. The implementation is just a handful of lines of code; take a look at MongoMq.
We are also able to control the guarantees which send gives us by using an appropriate write concern when writing new messages:
WriteConcern.W1ensures that once a send completes, the messages have been written to disk (but the buffers may not be yet flushed, so it's not a 100% guarantee) on a single node; this corresponds to asynchronous replicationWriteConcern.W2ensures that a message is written to at least 2 nodes (as we have 3 nodes in total, that's a majority) in the cluster; this corresponds to synchronous replication
The main downside of the Mongo-based queue is that:
- messages can't be received in bulk – the
find-and-modifyoperation only works on a single document at a time - when there's a lot of connections trying to receive messages, the collection will encounter a lot of contention, and all operations are serialised.
And this shows in the results: sends are faster than receives. But overall the performance is quite good!
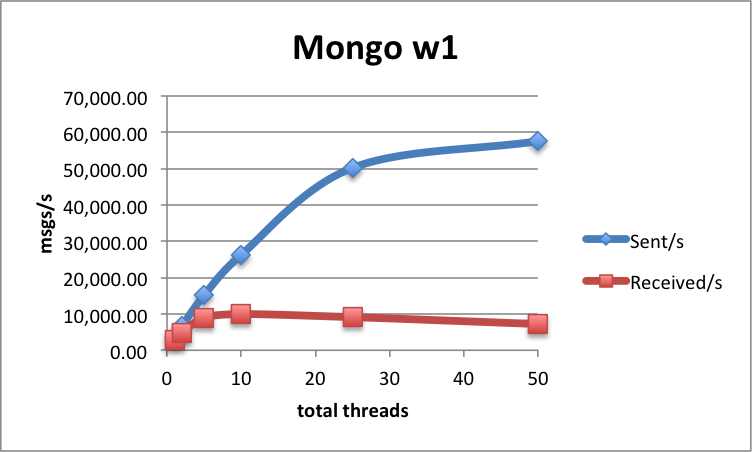
A single-thread, single-node, synchronous replication setup achieves 1 346 msgs/s sent and received. The maximum send throughput with multiple thread/nodes that we were able to achieve is about 25 038 msgs/s (25 threads, 2 nodes), while the maximum receive rate is 8 273 msgs/s (25 threads, 1 node).
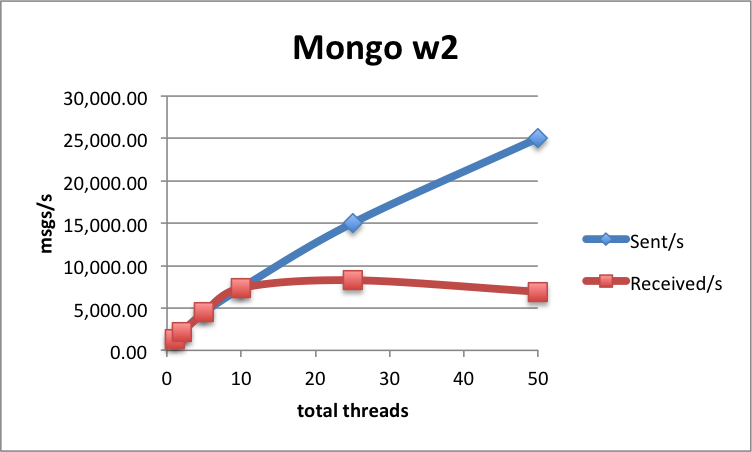
With asynchronous replication, the results are of course better: up to 57 555 msg/s sent and 9 937 msgs/s received. As you can see, here the difference between send and receive performance is even bigger. An interesting thing to note is that the receive throughput quickly achieves its maximum value, and adding more threads (clients) only decreases performance. The more concurrency, the lower overall throughput.
What about latencies? In both synchronous and asynchronous tests, the send latency is about 48 ms, and this doesn't deteriorate when adding more concurrent clients.
As for the processing latency, measurements only make sense when the receive rate is the same as the sending rate. When the clients aren't able to receive messages as fast as they are sent, the processing time goes arbitrarily up.
With 2 nodes running 5 threads each, Mongo achieved a throughput of 7 357 msgs/s with a processing latency of 48 ms. Anything above that caused receives to fall back behind sends. Here's the dashboard for that test:
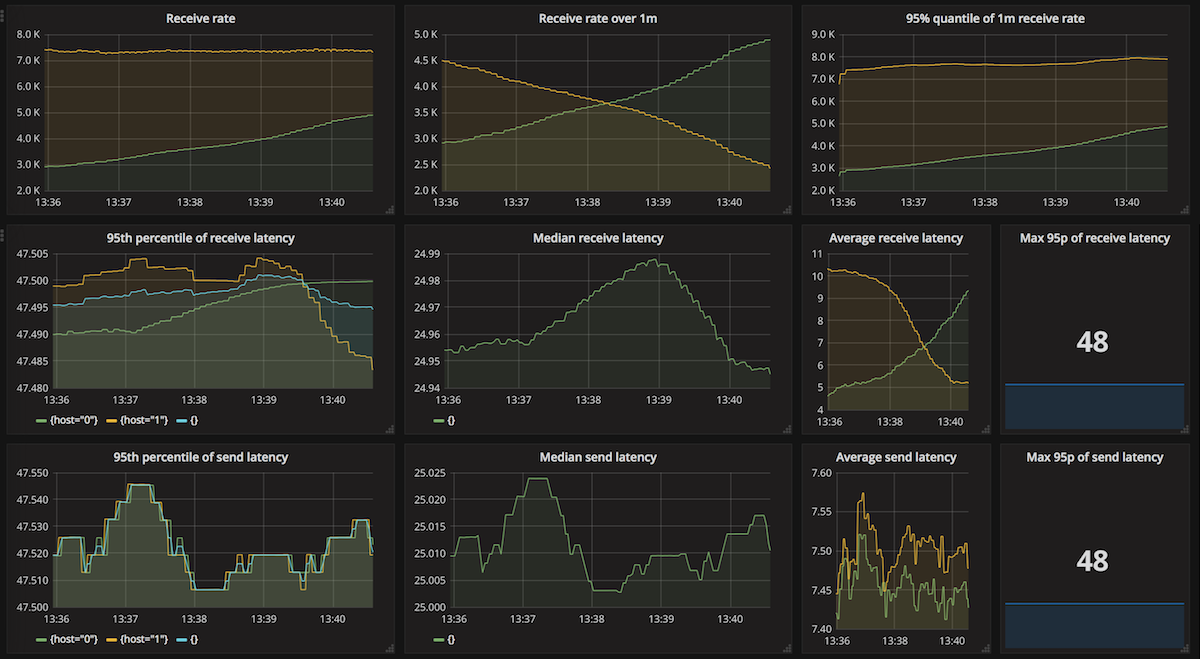
You might notice that the receive rates are a bit uneven - with both receiver nodes getting different amounts of messages. Results in detail when using synchronous replication:
| Threads | Nodes | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 1 346 | 1 346 | 47 | 48 |
| 5 | 1 | 4 461 | 4 461 | 47 | 48 |
| 25 | 1 | 15 020 | 8 273 | 48 | |
| 1 | 2 | 2 166 | 2 166 | 47 | 48 |
| 5 | 2 | 7 357 | 7 357 | 48 | 48 |
| 25 | 4 | 25 038 | 6 916 | 48 |
Overall, not bad for a very straightforward queue implementation on top of Mongo.
SQS
| Version | amazon java sdk 1.11.155 |
| Replication | ? |
SQS, Simple Message Queue, is a message-queue-as-a-service offering from Amazon Web Services. It supports only a handful of messaging operations, far from the complexity of e.g. AMQP, but thanks to the easy to understand interfaces, and the as-a-service nature, it is very useful in a number of situations.
SQS provides at-least-once delivery. It also guarantees that if a send completes, the message is replicated to multiple nodes; quoting from the website:
"Amazon SQS runs within Amazon's high-availability data centers, so queues will be available whenever applications need them. To prevent messages from being lost or becoming unavailable, all messages are stored redundantly across multiple servers and data centers."
We don't really know how SQS is implemented, but it most probably spreads the load across many servers, so including it here is a bit of an unfair competition: the other systems use a single fixed 3-node replicated cluster, while SQS can employ multiple replicated clusters and route/balance the messages between them. Still, it might be interesting to compare to self-hosted solutions.
A single thread on single node achieves 592 msgs/s sent and the same number of msgs received, with a processing latency of 130 ms and send latency of 72 ms.
These results are not impressive, but SQS scales nicely both when increasing the number of threads, and the number of nodes. On a single node, with 50 threads, we can send up to 16 982 msgs/s, and receive up to 6 892 msgs/s.
With 12 sender and 12 receiver nodes, these numbers go up to 90 361 msgs/s sent, and 80 069 msgs/s received! However, at these message rates, the service costs might outweigh the costs of setting up a self-hosted message broker.
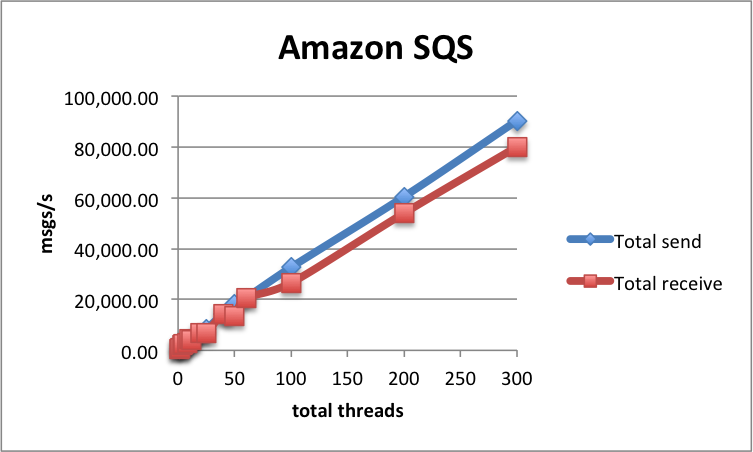
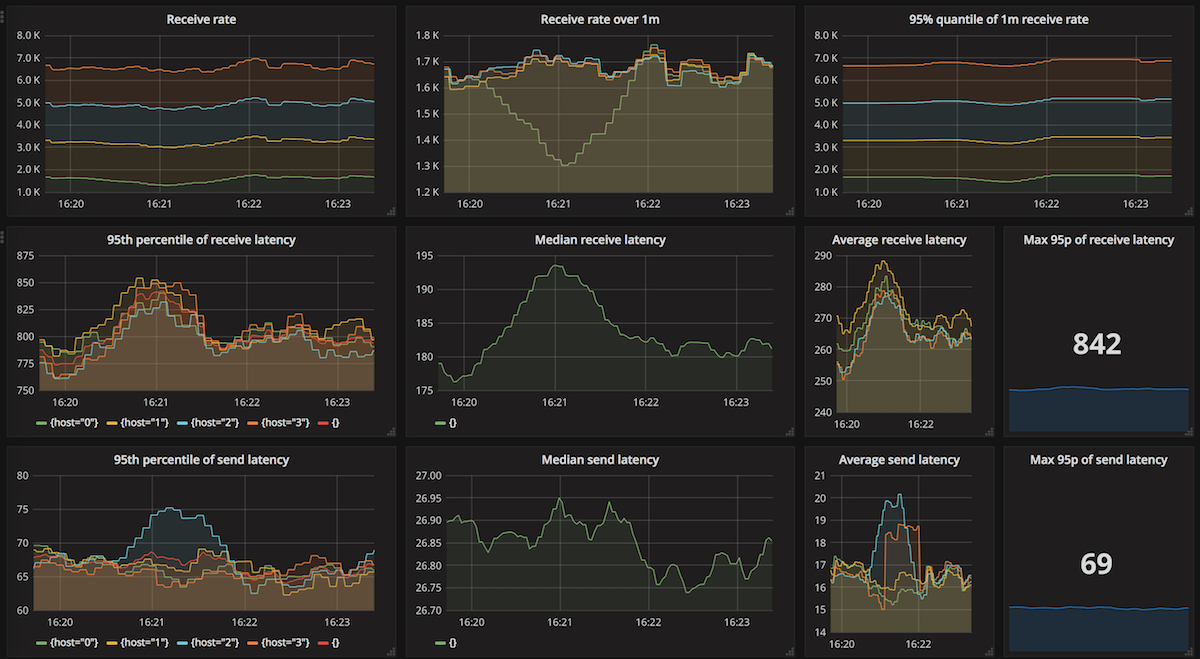
As for latencies, SQS is more unpredictable than other queues tested here. We've observed processing latency from 109 ms up to 1 366 ms. Send latencies are more constrained and are usually around 70 ms.
For a more detailed analysis of SQS's performance, see our article dedicated to the subject.
Finally, here's the dashboard for the test using 4 nodes, each running 5 threads.
RabbitMQ
| Version | 3.6.10-1, java amqp client 4.1.1 |
| Replication | synchronous |
RabbitMQ is one of the leading open-source messaging systems. It is written in Erlang, implements AMQP and is a very popular choice when messaging is involved; using RabbitMQ it is possible to define very complex message delivery topologies. It supports both message persistence and replication, with well documented behaviour in case of e.g. partitions.
We'll be testing a 3-node Rabbit cluster. To be sure that sends complete successfully, we'll be using publisher confirms, a Rabbit extension to AMQP, instead of transactions:
"Using standard AMQP 0-9-1, the only way to guarantee that a message isn't lost is by using transactions -- make the channel transactional, publish the message, commit. In this case, transactions are unnecessarily heavyweight and decrease throughput by a factor of 250. To remedy this, a confirmation mechanism was introduced."
The confirmations are cluster-wide (the queue was created with a policy using ha-mode: all, see the ha docs), so this gives us pretty strong guarantees: that messages will be both written to disk, and replicated to the cluster:
"When will messages be confirmed?
For routable messages, the basic.ack is sent when a message has been accepted by all the queues. For persistent messages routed to durable queues, this means persisting to disk. For mirrored queues, this means that all mirrors have accepted the message."
Such strong guarantees are probably one of the reasons for mediocre performance. A single-thread, single-node gives us 680 msgs/s sent&received, with a processing latency of 184 ms and send latency of 48 ms:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 680 | 680 | 99 | 48 |
| 1 | 5 | 2 154 | 2 148 | 107 | 48 |
| 1 | 25 | 3 844 | 3 844 | 122 | 66 |
| 2 | 1 | 844 | 843 | 109 | |
| 2 | 5 | 2 803 | 2 805 | 113 | |
| 2 | 25 | 3 780 | 3 784 | 141 | |
| 4 | 1 | 1 929 | 1 930 | 99 | |
| 4 | 5 | 3 674 | 3 673 | 126 | |
| 4 | 25 | 4 331 | 4 330 | 179 | 504 |
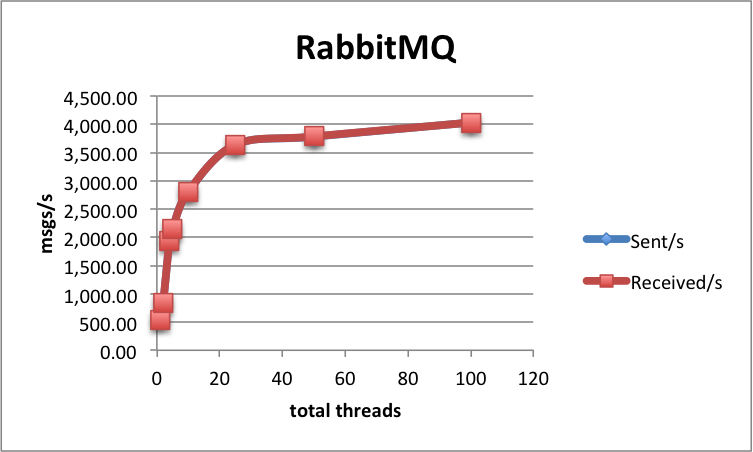
This scales nicely as we add threads/nodes, up to 4 330 msgs/s using 4 sending/receiving nodes running 25 threads each, which seems to be the maximum that Rabbit can achieve.
Let's analyze this case more closely; here's the test dashboard. As you can see, the receive rates are fairly stable between 4 000 and 5 000 msgs/s. Also the processing latency is mostly the same throughout the test, with the 95th percentile at 179 ms. However, the send latency goes up to 504 ms for brief periods of time. Hence in some cases messages are already processed, even before the send completes! However, for most of the time the send latency is between 150-250 ms.
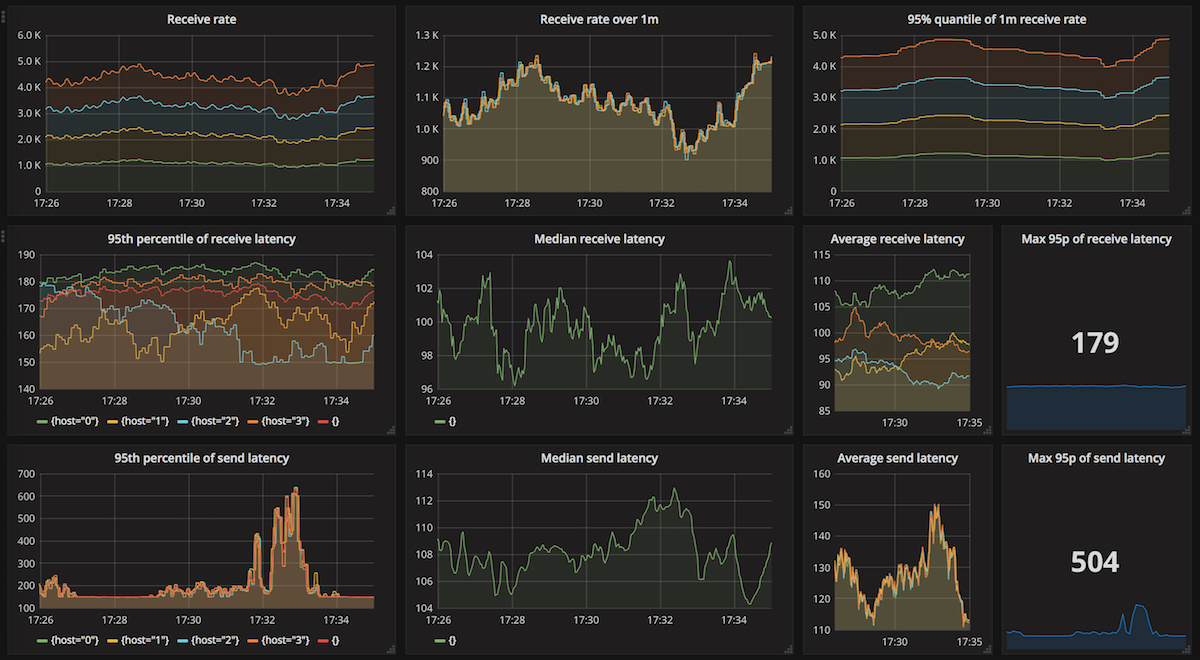
Note that messages are always sent and received at the same rate, which would indicate that message sending is the limiting factor when it comes to throughput. Rabbit's performance is a consequence of some of the features it offers, for a comparison with Kafka see for example this Quora question.
The RabbitMq implementation of the Mq interface is again pretty straightforward. We are using the mentioned publisher confirms, and setting the quality-of-service when receiving so that at most 100 messages are delivered unconfirmed (in-flight).
Interestingly, sending the messages in larger batches doesn't affect overall throughput much, with 4 550 msgs/s when using batches of 100 and 5 004 msgs/s when we batch up to 1000 messages (test dashboard).
An important side-node: RabbitMQ has a great web-based console, available with almost no setup, which offers some very good insights into how the queue is performing.
ActiveMQ
| Version | 5.14.3 |
| Replication | configurable, asynchronous & synchronous |
ActiveMQ is one of the most popular message brokers. In many cases it's "the" messaging server when using JMS. However, it gained replication features only recently. Until version 5.9.0, it was possible to have a master-slave setup using a shared file system (e.g. SAN) or a shared database; these solutions require either specialised hardware, or are constrained by a relational database (which would have to be clustered separately).
However, it is now possible to use the Replicated LevelDB storage, which uses Zookeeper for cluster coordination (like Kafka).
Replication can be both synchronous and asynchronous; in fact, there's a lot of flexibility. By setting the sync configuration option of the storage, we can control how many nodes have to receive the message and whether it should be written to disk or not before considering a request complete:
quorum_memcorresponds to synchronous replication, where a message has to be received by a majority of servers and stored in memoryquorum_diskis even stronger, requires the message to be written to disklocal_memis asynchronous replication, where a message has to be stored in memory only. Even if disk buffers are flushed, this doesn't guarantee message delivery in case of a server restartlocal_diskis asynchronous replication where a message has to be written to disk on one server
In the tests we'll be mainly using quorum_mem, with a cluster of 3 nodes. As we require a quorum of nodes, this setup should be partition tolerant, however there's no documentation on how partitions are handled and how ActiveMQ behaves in such situations.
The ActiveMq implementation uses standard JMS calls using the OpenWire protocol to connect to the ActiveMQ server. For sends, we create a producer with delivery mode set to PERSISTENT, and for receives we create a consumer with CLIENT_ACKNOWLEDGE, as we manually acknowledge message delivery.
Performance-wise, ActiveMQ does a bit worse than RabbitMQ, achieving at most 3 857 msgs/s with synchronous replication. This seems to be the maximum and is achieved with 1 node and 25 threads:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 395 | 395 | 48 | |
| 1 | 5 | 1 182 | 1 181 | 97 | 48 |
| 1 | 25 | 3 857 | 3 855 | 284 |
At the highest throughput, the receive rates are quite stable between 3 700 and 4 100 msg/s. The processing latency is also quite tightly bound and at most 284 ms.
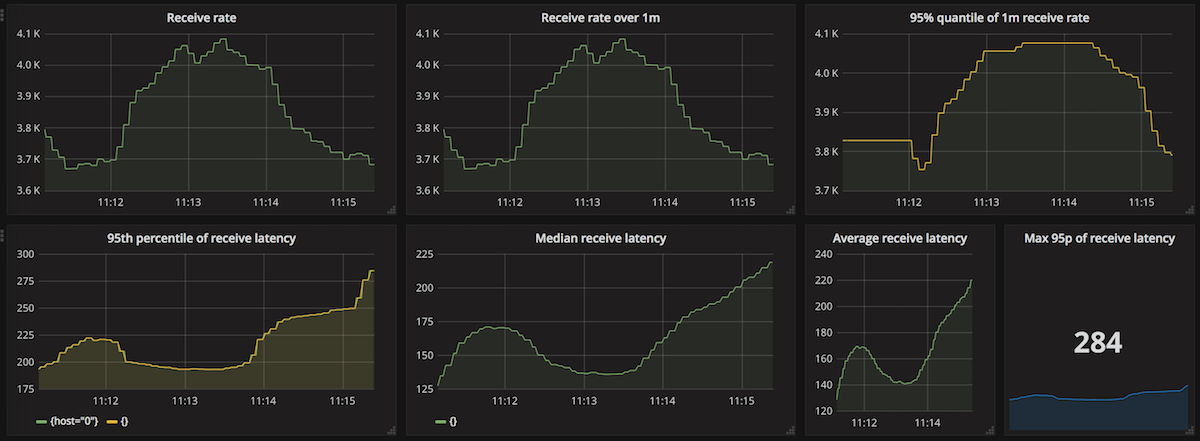
Adding more nodes doesn't improve the results, in fact, they are slightly worse. Interestingly, using the stronger quorum_disk guarantee has no big effect on performance:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Notes |
|---|---|---|---|---|---|
| 1 | 25 | 3 857 | 3 855 | 284 | quorum_mem |
| 2 | 25 | 2 862 | 2 869 | 778 | quorum_mem |
| 4 | 25 | 2 225 | 2 224 | 1071 | quorum_mem |
| 4 | 5 | 2 659 | 2 658 | 636 | quorum_disk |
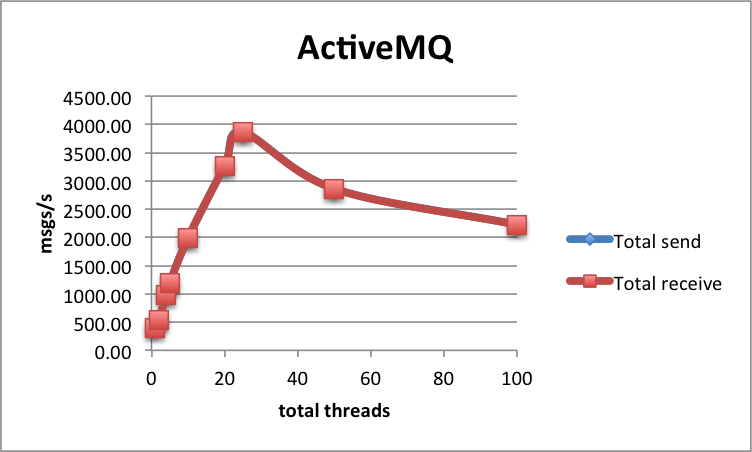
Same as with RabbitMQ, in all tests sends and receives happen at the same rates, hence the bottleneck in terms of throughput is the sending side.
Artemis
| Version | 2.2.0, java driver 2.2.0 |
| Replication | synchronous |
Artemis is the proposed successor to ActiveMQ, and might some day become ActiveMQ 6. It emerged from a donation of the HornetQ code (which is no longer maintained) to Apache, and is being developed by both RedHat and ActiveMQ developers. Like RabbitMQ, it supports AMQP, as well as other messaging protcolos, for example STOMP and MQTT.
Artemis supports a couple of high availability alternatives, either using replication or a shared store. Here we'll be using the over-the-network option, that is live-backup pairs. Unlike the other brokers tested so far, in such a setup data is replicated only to one other node (the backup). The configuration explicitly states which server is the master and backup one.
However, to avoid split-brain issues in case of partitions 2 servers are not enough. That's why it's possible to setup a 3-node cluster, where the 3rd node is used by the master/slave in case of a network failure to determine if there's a majority of servers visible.
Although it is not clearly stated in the documentation (see send guarantees), replication is synchronous, hence when a message send completes, we can be sure that messages are written to journals on both nodes. That is similar to Rabbit, and corresponds to Mongo's replica-safe write concern and ActiveMQ's quorum_mem.
The Artemis test client code is almost the same as for ActiveMQ, as both are based on JMS. One difference is using an Artemis-specific connection factory, see ArtemisMq.
During initial testing, we've been using the default NIO journal type. However, as pointed out by Artemis's authors, in this clusterd setup it's better to use the memory-mapped journal. Also, in the clustered deployment there's no need to require an fsync before a write completes (it's enough that the data is replicated). And indeed these changes, together with improving the jms client, improved the performance three-fold.
In summary, the configuration changes comparing to the default are:
- the
Xmxjava parameter bumped to16G - in
broker.xml, theglobal-max-sizesetting changed to8G journal-typeset toMAPPEDjournal-datasync,journal-sync-non-transactionalandjournal-sync-transactionalall set to false
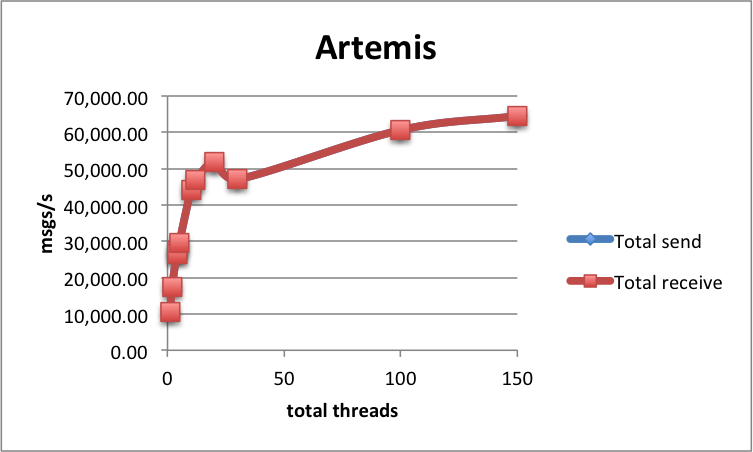
Performance wise, Artemis does great. A single-node, single-thread setup achieves 10 536 msgs/s. With 5 threads, we are up to 29 476 msgs/s, and by adding nodes, we can scale that result to 64 485 msgs/s using 6 nodes and 25 threads. In that last case, the 95th percentile of send latency is a stable 48 ms (with the average at 12.5 ms) and maximum processing latency of 122 ms:
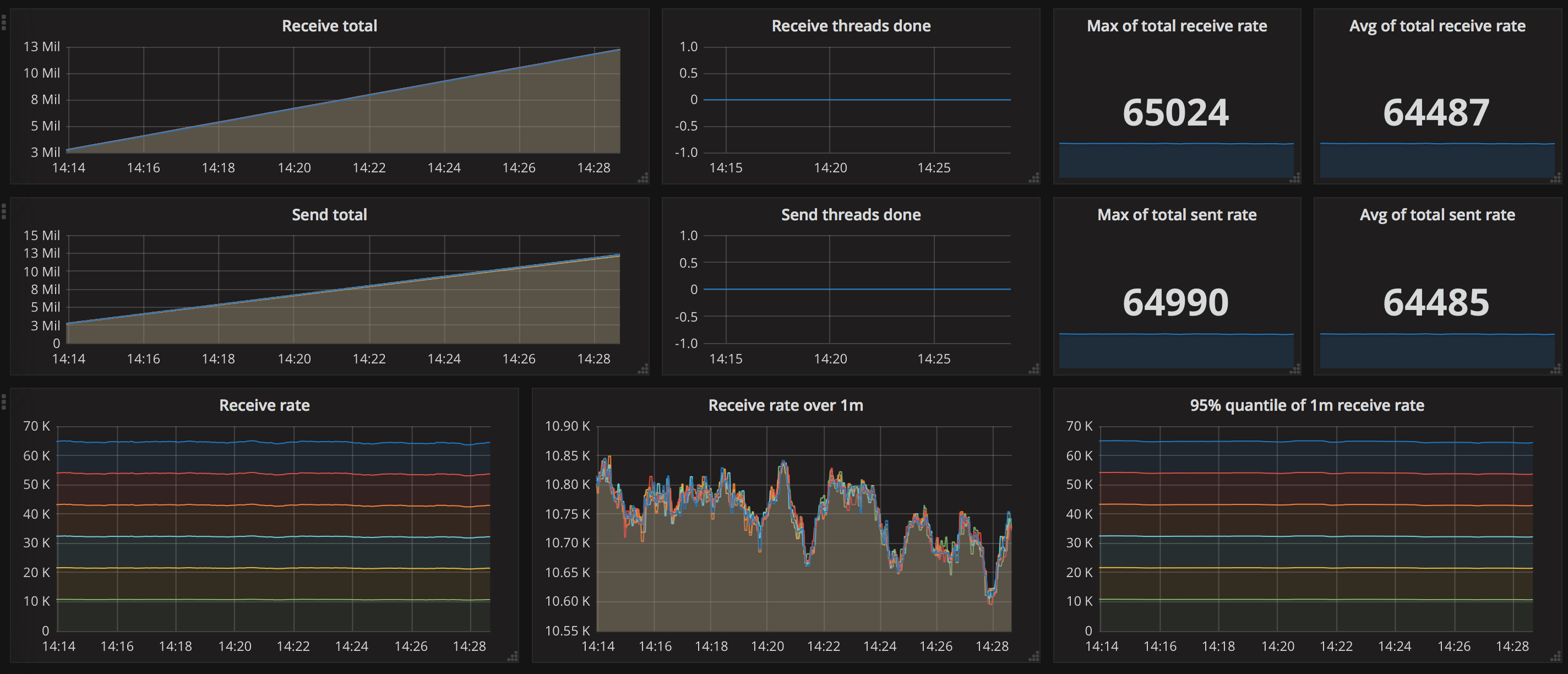
Here are all of the results. As you can see, Artemis shows impressive preformance numbers, keeping both the send and processing latencies low:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 10 536 | 10 536 | 48 | 45 |
| 1 | 5 | 29 476 | 29 476 | 48 | 47 |
| 2 | 1 | 17 515 | 17 515 | 46 | 46 |
| 2 | 5 | 44 003 | 44 003 | 46 | 47 |
| 4 | 1 | 27 197 | 27 197 | 47 | 47 |
| 4 | 5 | 51 724 | 51 720 | 46 | 47 |
| 4 | 25 | 60 619 | 60 619 | 62 | 48 |
| 6 | 5 | 47 078 | 47 082 | 47 | 48 |
| 6 | 25 | 64 485 | 64 487 | 122 | 48 |
Kafka
| Version | 0.11.0.0 |
| Replication | configurable, asynchronous & synchronous |
Kafka takes a different approach to messaging. The server itself is a streaming publish-subscribe system, or at an even more basic level, a distributed log. Each Kafka topic can have multiple partitions; by using more partitions, the consumers of the messages (and the throughput) may be scaled and concurrency of processing increased.
On top of publish-subscribe with partitions, a point-to-point messaging system is built, by putting a significant amount of logic into the consumers (in the other messaging systems we've looked at, it was the server that contained most of the message-consumed-by-one-consumer logic; here it's the consumer).
Each consumer in a consumer group reads messages from a number of dedicated partitions; hence it doesn't make sense to have more consumer threads than partitions. Messages aren't acknowledged on server (which is a very important design difference!), but instead processed message offsets are managed by consumers and written back to a special Kafka store (or a client-specific store), either automatically in the background, or manually. This allows Kafka to achieve much better performance.
Such a design has a couple of consequences:
- only messages from each partition are processed in-order. A custom partition-routing strategy can be defined
- all consumers should consume messages at the same speed. Messages from a slow consumer won't be "taken over" by a fast consumer
- messages are acknowledged "up to" an offset. That is messages can't be selectively acknowledged.
- no "advanced" messaging options are available, such as routing or delaying message delivery.
You can read more about the design of the consumer in Kafka's docs. It is also possible to add a layer on top of Kafka to implement individual message acknowledgments and re-delivery, see our article on the performance of kmq.
To achieve guaranteed sends and at-least-once delivery, we used the following configuration (see the KafkaMq class):
- topic is created with a
replication-factorof3 - for the sender, the
request.required.acksoption is set to1(asynchronous replication - a send request blocks until it is accepted by the partition leader) or-1(synchronous replication; in conjunction withmin.insync.replicastopic config set to2a send request blocks until it is accepted by at least 2 replicas - a quorum when we have 3 nodes in total) - consumer offsets are committed every 10 seconds manually; during that time, message receiving is blocked (a read-write lock is used to assure that). That way we can achieve at-least-once delivery (only committing when messages have been "observed").
Now, to the results. Kafka's performance is great. With synchronous replication, a single-node single-thread achieves about 2 391 msgs/s, and the best result is 54 494 msgs/s with 25 sending&receiving threads and 6 client sender/receiver nodes.
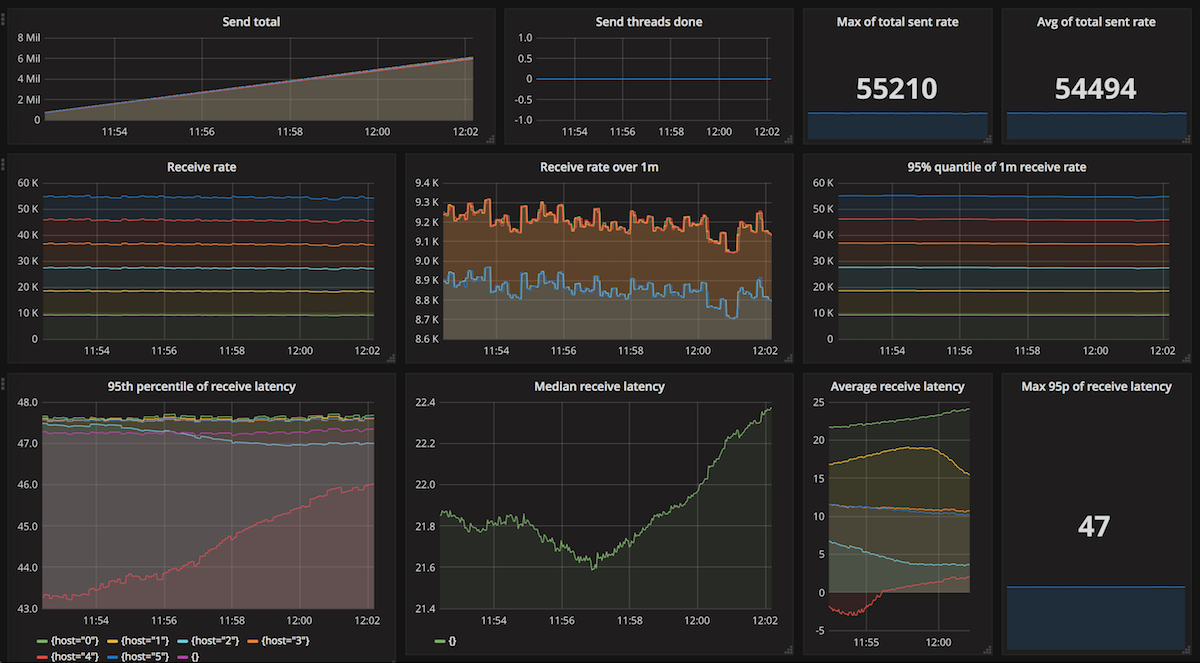
As you can see, the receive rates are very stable. The 95th percentile of the processing latency is also a stable 47 ms. The send latencies are also around 48 ms. Here's a summary of all of the results:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 2 391 | 2 391 | 48 | 48 |
| 1 | 5 | 9 917 | 9 917 | 48 | 48 |
| 1 | 25 | 20 982 | 20 982 | 46 | 48 |
| 2 | 1 | 4 957 | 4 957 | 47 | |
| 2 | 5 | 17 470 | 17 470 | 47 | |
| 2 | 25 | 41 902 | 41 901 | 45 | 48 |
| 4 | 1 | 9 149 | 9 149 | 47 | |
| 4 | 5 | 24 381 | 24 381 | 47 | 48 |
| 4 | 25 | 47 617 | 47 618 | 47 | 48 |
| 6 | 25 | 54 494 | 54 494 | 47 | 48 |
| 8 | 25 | 53 696 | 53 697 | 47 | 48 |
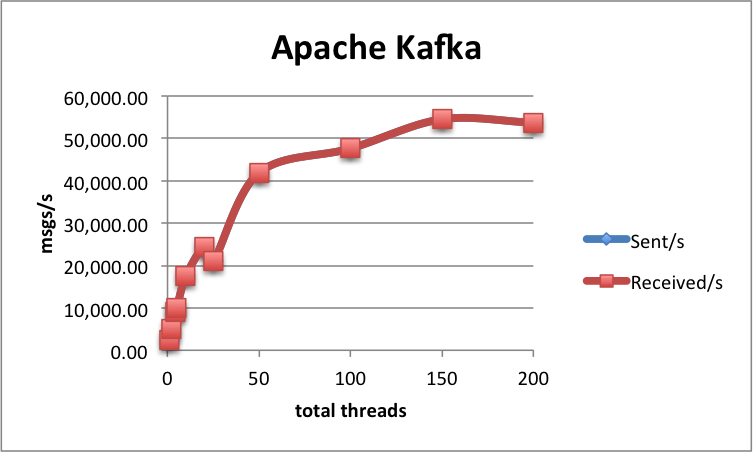
Above 6 nodes adding more client threads doesn't increase performance - that's possibly the most we can get out of a 3-node Kafka cluster. However, Kafka has a big scalability potential, by adding nodes and increasing the number of partitions.
We could also scale up the batches: by using batches of up to 100, we can achieve 102 170 msgs/s with 4 client nodes, and with batches of up to 1000, a whooping 141 250 msgs/s. However, the processing latency then increases to 443 ms.
Event Store
| Version | 4.0.1, JVM client 4.1.1 |
| Replication | synchronous |
EventStore is first and foremost a database for event sourcing and complex event processing. Only some time age support for the competing consumers pattern, or as we know it message queueing was added. How does it stack up comparing to other message brokers?
EventStore offers a lot in terms of creating event streams, subscribing to them and transforming through projections. In the tests we'll only be writing events to a stream (each message will become an event), and create persistent subscriptions (that is, subscriptions where the state is stored on the server) to read events on the clients. You can read more about event sourcing, competing consumers and subscription types in the docs.
As all of the tests are JVM-based, here also we'll be using the JVM client, which is built on top of Akka and hence fully non-blocking. However, the test framework is synchronous - hence the EventStoreMq implementation hides the asynchronous nature behind synchronous sender and receiver interfaces. Even though the tests will be using multiple threads, all of them will be using only one connection to EventStore per node!
Comparing to the default configuration, the client has a few modified options:
readBatchSize,historyBufferSizeandmaxCheckPointSizeare all bumped to1000to allow more messages to be pre-fetched- the in-flight messages buffer size is increased from the default
10to a1000. As this is by default not configurable in the JVM client, we had to copy some code from the driver and adjust the properties (see theMyPersistentSubscriptionActorclass)
How does EventStore's perform? Very good! A single sender/receiver node achieves 4 494 msgs/s, and when using 8 sender and 8 receiver nodes, in the tests we have achieved a throughput of 17 093 msgs/s with the 95th percentile of processing latency being at most 154 ms and the send latency 95 ms (average around 55 ms). Receive rates are stable, as are the latencies:
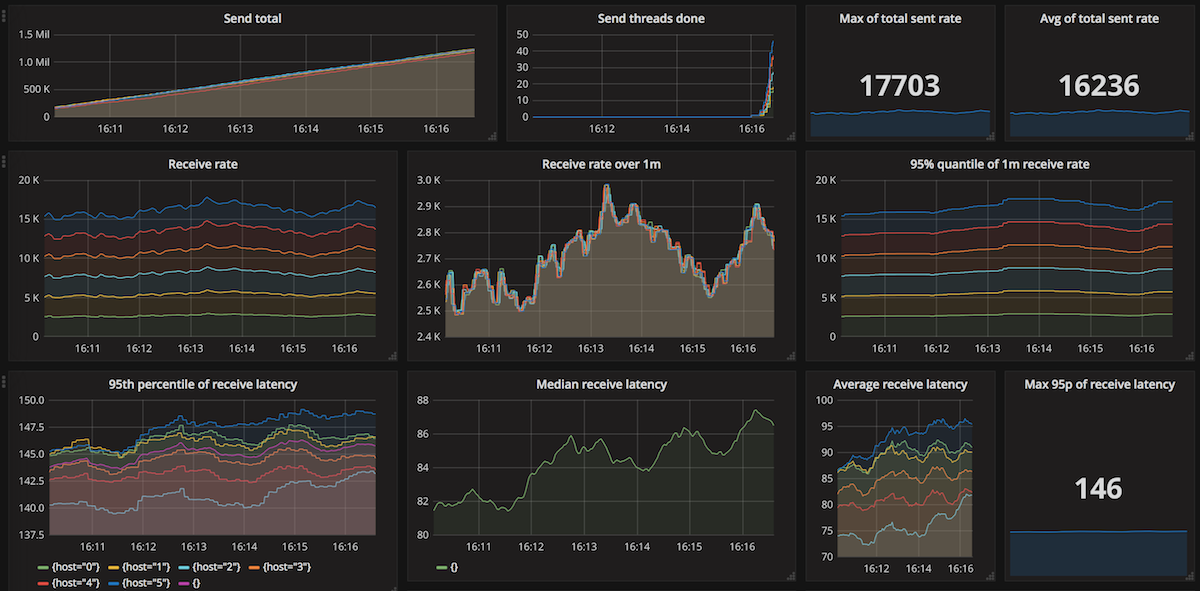
Here's a summary of all of the EventStore tests that we have run:
| Nodes | Threads | Send msgs/s | Receive msgs/s | Processing latency | Send latency |
|---|---|---|---|---|---|
| 1 | 1 | 78 | 78 | 121 | 49 |
| 1 | 25 | 4 494 | 4 493 | 136 | 48 |
| 2 | 25 | 7 923 | 7 917 | 136 | 48 |
| 2 | 35 | 10 160 | 10 157 | 135 | 49 |
| 4 | 25 | 13 616 | 13 614 | 137 | 50 |
| 6 | 25 | 16 236 | 16 229 | 146 | 87 |
| 8 | 25 | 17 093 | 17 092 | 154 | 95 |
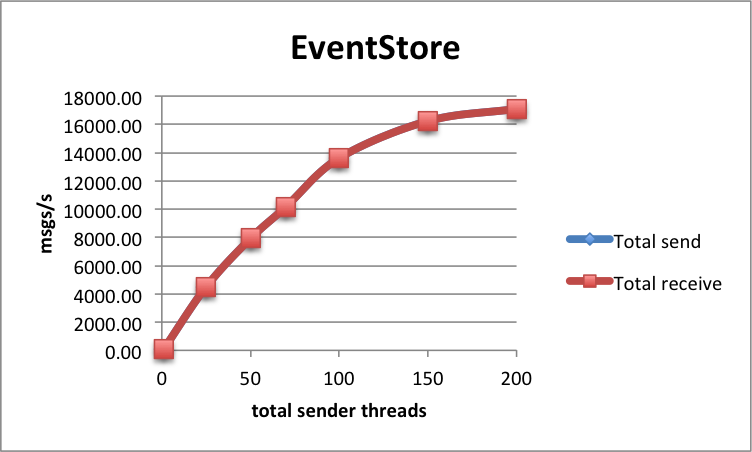
EventStore also provides a handy web console, however its setup on EC2 isn't trivial.
Summary
As always, which message queue to choose depends on specific project requirements. All of the above solutions have some good sides:
- SQS is a service, so especially if you are using the AWS cloud, it's an easy choice: good performance and no setup required. It's cheap for low to moderate workloads, but might get expensive with high load
- if you are already using Mongo, it is easy to build a replicated message queue on top of it, without the need to create and maintain a separate messaging cluster
- if you want to have high persistence guarantees, RabbitMQ ensures replication across the cluster and on disk on message send. It's a very popular choice used in many projects, with full AMQP implementation and support for many messaging topologies
- ActiveMQ is a popular and widely used messaging broker with moderate performance, wide protocol support
- Artemis offers the best perfomance (on par with Kafka) with the familiarity of JMS and a wide range of supported protcols AMQP/STOMP/MQTT support
- Kafka offers the best performance (on par with Artemis) and scalability, at the cost of feature set
- EventStore can be your central storage for events with complex event processing capabilities and great performance
When looking only at the throughput, Kafka and Artemis are clear winners (unless we include SQS with multiple nodes, but as mentioned, that would be unfair):
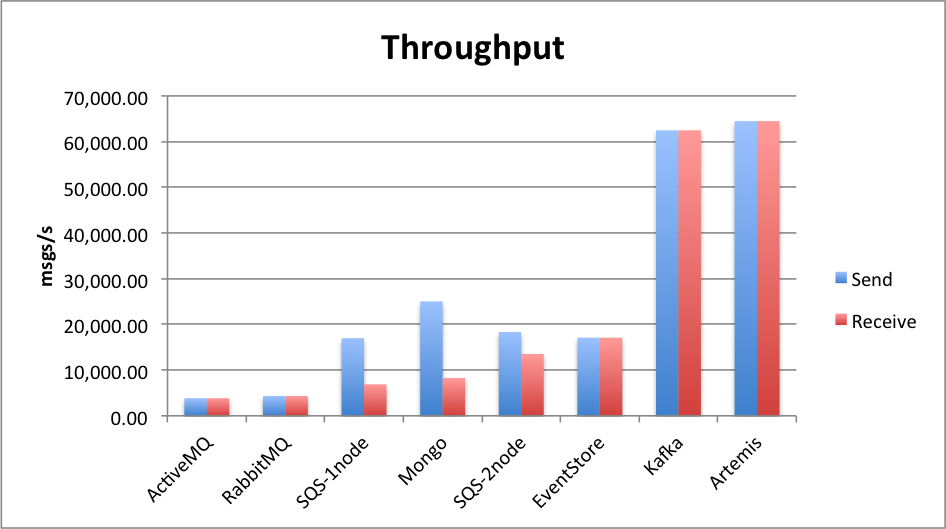
The 95th percentile of send latency is uniformly low (around 50ms) with the exception of Rabbit under higher load:
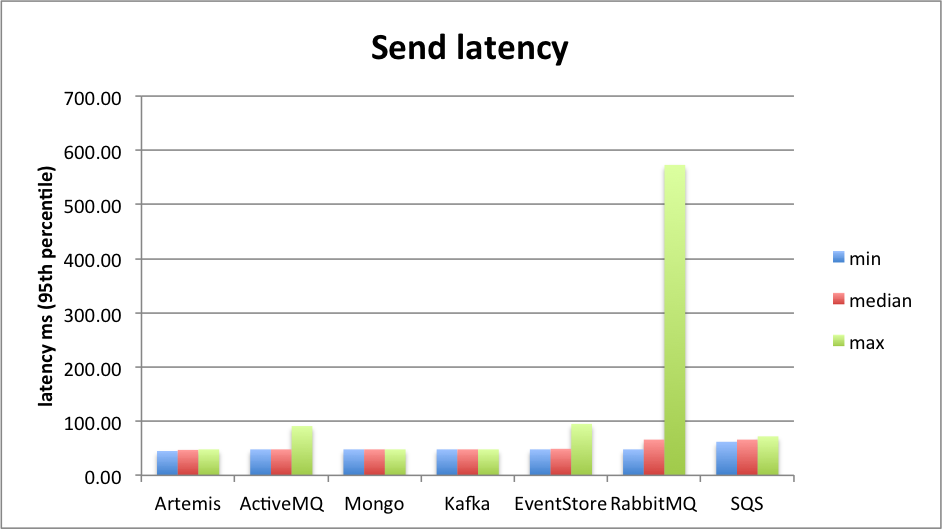
Finally, the processing latency has a wider distribution across the brokers. Usually, it's below 150ms - with Kafka, ActiveMQ and SQS faring worse under high load:
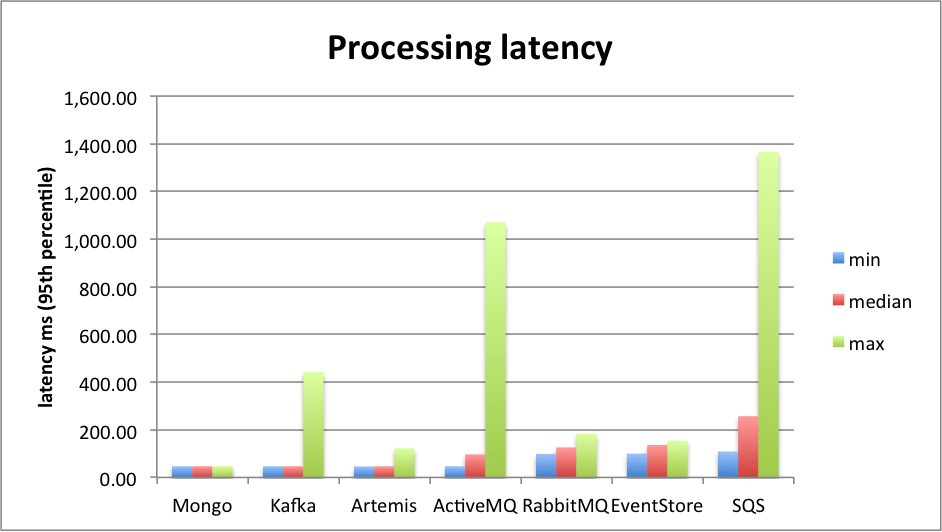
There are of course many other aspects besides performance, which should be taken into account when choosing a message queue, such as administration overhead, partition tolerance, feature set regarding routing, etc. While there's no message-queueing silver bullet, hopefully these benchmarks will be useful when choosing the best system for your project!
Credits
The following team members contributed to this work: Grzegorz Kocur, Maciej Opała, Marcin Kubala, Krzysztof Ciesielski, Adam Warski. Clebert Suconic, Michael André Pearce and Greg Young helped out with some configuration aspects of Artemis and EventStore. Thanks!
The latest version of this article is currently available here - enjoy!